Blind vs. Traditional Proficiency Testing: A 2025 Comparative Analysis for Biomedical Research
This article provides a comparative analysis of blind and traditional proficiency testing methodologies, tailored for researchers and professionals in drug development and clinical diagnostics.
Blind vs. Traditional Proficiency Testing: A 2025 Comparative Analysis for Biomedical Research
Abstract
This article provides a comparative analysis of blind and traditional proficiency testing methodologies, tailored for researchers and professionals in drug development and clinical diagnostics. It explores the foundational principles of both approaches, details their practical application across laboratory and clinical trial settings, and addresses key implementation challenges. The analysis synthesizes current regulatory trends, including recent CLIA updates, and offers evidence-based insights to guide the selection, optimization, and validation of testing strategies to enhance data integrity, reduce bias, and ensure regulatory compliance in biomedical research.
Defining the Paradigms: Core Concepts in Traditional and Blind Proficiency Testing
Defining Traditional Declared Proficiency Testing
Traditional Declared Proficiency Testing (PT) is a fundamental quality assurance process where laboratories analyze samples of unknown values provided by an external source to evaluate their analytical performance. After testing, laboratories receive comparative data showing their results alongside those from other laboratories that tested the same specimens, enabling them to identify potential issues and implement corrective actions [1].
This form of testing serves as an external quality control mechanism, contrasting with internal quality checks. Originally developed as an educational tool to help laboratories investigate procedural problems, it has evolved into a mandatory requirement for accreditation and regulatory compliance across numerous testing industries [1] [2]. In declared PT—the most common format—participants know they are being tested, which distinguishes it from blind proficiency testing where analysts are unaware they are evaluating test samples [3] [4].
The Operational Framework of Declared Proficiency Testing
Core Components and Process Flow
The traditional declared PT process follows a standardized workflow with distinct stages and key participants. The sequence below outlines the primary steps in a single PT cycle:
Regulatory Context and Requirements
For many laboratories, participation in declared PT programs is not optional but mandated by regulatory frameworks:
- Clinical Laboratory Improvement Amendments (CLIA): Requires most U.S. facilities performing tests on human specimens to participate in approved PT programs, with specific requirements for test frequency and sample numbers [1]
- ISO/IEC 17025:2017: International standard for testing laboratories requiring participation in proficiency testing as evidence of technical competence [5]
- ISO/IEC 17043:2010: Provides the conformity assessment for PT providers, ensuring they operate under standardized quality systems [6]
Regulated analytes under CLIA require laboratories to analyze five samples or "challenges" across three shipments annually [1]. This structured approach helps ensure consistent quality monitoring throughout the year.
Experimental Protocols in Declared Proficiency Testing
Standardized Implementation Methodology
The experimental protocol for traditional declared PT follows rigorous standardization to ensure fair assessment across participating laboratories:
Sample Development: PT providers create characterized samples with predetermined values that closely mimic real patient, environmental, or product samples [2]. These samples are homogeneous and stable to ensure all participants receive equivalent materials.
Sample Distribution: Providers ship blind-coded samples to participating laboratories according to a predefined schedule, typically three times annually for regulated tests [1].
Laboratory Analysis: Participating laboratories analyze the PT samples using their standard methods, equipment, and personnel. The testing is performed with the knowledge that it is a proficiency assessment, but without knowing the expected values [2].
Result Submission: Laboratories confidentially report their analytical results to the PT provider within specified deadlines.
Performance Assessment: PT providers statistically evaluate each laboratory's results against pre-established acceptable performance criteria, which may include peer group comparisons and deviation from assigned values [2].
Grading and Reporting: Participants receive detailed reports showing their performance relative to peers and whether they met acceptance criteria, enabling identification of potential areas for improvement.
Veterinary Diagnostic Case Study Protocol
A 2025 study demonstrated a comprehensive approach to declared PT in veterinary diagnostics [7]. Fourteen veterinary diagnostic laboratories participated in an exercise to identify the root cause of simulated lead toxicosis in cattle using a multi-step methodology:
- Materials Provided: Participants received a clinical case description, digitized brain histology slides, and tissue samples (liver and brain) for optional chemical analysis [7]
- Experimental Timeline: Laboratories had 14 days to report histopathologic findings and differential diagnoses, and 21 days total to complete chemical analyses and final diagnosis [7]
- Assessment Criteria: Performance was evaluated across multiple competencies including histology interpretation, differential diagnosis formulation, appropriate test selection, analytical accuracy, and final diagnosis [7]
- Outcome Measurement: Thirteen of fourteen laboratories successfully diagnosed lead toxicosis by correctly completing all investigative stages [7]
Key Research Reagents and Materials
Table: Essential Components in Proficiency Testing Programs
| Component | Function | Quality Requirements |
|---|---|---|
| PT Samples | Unknown test materials for analysis | Homogeneous, stable, matrix-matched to routine samples [2] |
| Certified Reference Materials (CRMs) | Calibration and quality control | Certified values with established uncertainty, ISO 17034 accredited [2] |
| Method Validation Documents | Verify test procedures are fit for purpose | Established accuracy, precision, linearity, LOD/LOQ [2] |
| Statistical Analysis Package | Performance evaluation and peer comparison | Compliance with ISO 13528:2005 statistical methods [6] |
| Quality Control Materials | Internal process monitoring | Commutable with patient samples, well-characterized [2] |
Performance Data and Market Context
Adoption Rates and Comparative Effectiveness
Table: Declared vs. Blind Proficiency Testing Adoption and Characteristics
| Characteristic | Traditional Declared PT | Blind PT |
|---|---|---|
| Adoption in Forensic Labs | ~90% of U.S. forensic laboratories [4] | ~10% of U.S. forensic laboratories [4] |
| Analyst Awareness | Analysts know they are being tested | Analysts unaware they are being tested |
| Error Rate Detection | May not reflect real-world error rates due to heightened awareness | More accurately reflects routine performance and true error rates [8] |
| Implementation Complexity | Relatively straightforward, well-established protocols | Logistically challenging, requires external cooperation [3] |
| Cultural Acceptance | Widely accepted, minimal resistance | May challenge "myth of 100% accuracy" in some fields [4] |
Market Presence and Economic Impact
The laboratory proficiency testing market reflects the widespread adoption of declared PT schemes across industries:
- The global laboratory PT market was valued at USD 1.58 billion in 2025 and is projected to reach USD 1.98 billion by 2030, representing a 6.5% compound annual growth rate [5]
- Clinical diagnostics represents the largest segment with 38.67% market share in 2024, driven largely by regulatory mandates [5]
- Independent/third-party providers dominate the market with 54.45% share, highlighting the preference for vendor-neutral schemes [5]
Advantages and Limitations in Research Applications
Strengths of Traditional Declared PT
- Educational Value: Serves as a powerful teaching tool for laboratory staff to recognize methodological limitations and improve techniques [1]
- Comparative Benchmarking: Provides interlaboratory comparison that helps laboratories understand their performance relative to peers [2]
- Regulatory Compliance: Meets accreditation requirements for major regulatory bodies including CLIA and ISO [1] [5]
- Process Improvement: Identifies specific areas needing corrective action through standardized performance metrics [2]
Limitations and Methodological Considerations
- Potential for Enhanced Performance: Knowing they are being tested may cause analysts to exercise special care, potentially producing results that don't reflect routine performance [3]
- Limited Error Rate Data: May not detect all sources of error present in the complete testing process from sample receipt to reporting [8]
- Behavioral Modification: The knowledge of testing can change normal workflow patterns, reducing the ecological validity of the assessment [3]
Traditional declared proficiency testing represents the foundational approach to external quality assessment across diagnostic, forensic, and research laboratories. While it provides essential comparative data and educational value for continuous improvement, its limitations—particularly the potential for altered behavior when analysts know they are being tested—have prompted the development and increasing adoption of blind proficiency testing methods.
For researchers and drug development professionals, understanding both declared and blind PT methodologies is crucial for designing comprehensive quality systems. The optimal approach often involves implementing both methods strategically: using declared PT for educational development and method validation, while incorporating blind PT to obtain more realistic error rate data and validate the entire testing pipeline under routine operational conditions [3] [8]. This integrated strategy provides the most complete assessment of laboratory performance, supporting the generation of reliable, reproducible scientific data across all research and diagnostic applications.
In the rigorous world of scientific validation and product development, the methodology used for performance assessment can significantly influence outcomes and interpretations. Traditional proficiency testing, long considered the gold standard across various scientific disciplines, operates on a fundamental premise: participants know they are being evaluated using standardized materials under controlled conditions. While this approach provides valuable benchmarking data, it introduces potential biases that can compromise the real-world applicability of results. The emerging paradigm of blind testing represents a fundamental shift toward assessment methodologies that mirror authentic usage scenarios, delivering unbiased data that more accurately predicts real-world performance.
This comparative analysis examines the fundamental distinctions between these two methodological approaches, with a specific focus on their application in cutting-edge technological and scientific fields. Through detailed experimental data and case studies, we demonstrate how blind testing methodologies uncover performance insights that traditional proficiency testing often misses. As assessment protocols evolve, understanding the relative advantages, limitations, and appropriate applications of each approach becomes crucial for researchers, product developers, and quality assurance professionals aiming to make data-driven decisions based on the most reliable validation data possible.
Understanding the Methodological Spectrum
Traditional Proficiency Testing: Structured Assessment with Known Samples
Traditional proficiency testing represents a structured approach to evaluation where analysts or laboratories are assessed using standardized reference materials with known expected outcomes. This system has formed the backbone of quality assurance programs across numerous industries, particularly in regulated fields like food safety and clinical diagnostics.
The U.S. Food and Drug Administration's Grade "A" Milk Proficiency Testing Program exemplifies a mature, well-integrated proficiency testing system. This program annually distributed blinded milk samples to certified laboratories nationwide, requiring analysis for key safety parameters including bacterial counts, coliform levels, somatic cell counts, and antibiotic residues [9]. Laboratories analyzed these samples using prescribed methodologies and reported their results to the FDA's Moffett Center Proficiency Testing Laboratory for statistical analysis against expected values [9]. This system operated under a cooperative federal-state structure, with the National Conference on Interstate Milk Shipments (NCIMS) providing oversight and uniform standards across all participating laboratories [9]. The program demonstrated measurable success in improving laboratory performance over time, with peer-reviewed data showing a steady increase in correct results reported by laboratories from 2012 to 2018 [9].
Blind Testing: Real-World Evaluation Through Anonymous Assessment
Blind testing adopts a fundamentally different approach by removing the awareness of evaluation from the testing process. In this methodology, evaluators make comparative assessments without knowing the identity of the products, systems, or solutions they are evaluating. This approach effectively eliminates various forms of bias, including brand preference, expectation effects, and contextual influences that can consciously or subconsciously influence human judgment.
The LMArena platform, developed by the University of California, Berkeley, implements a sophisticated blind testing framework for evaluating AI models [10]. This platform presents users with anonymous outputs from different AI systems and collects preference data based solely on perceived quality without brand identification. This "blind" evaluation mechanism has become an internationally recognized benchmark for AI model performance, with recent assessments involving 26 competing models in a head-to-head comparison [10]. The platform's massive global user base generates substantial preference data that directly shapes public performance rankings, making it one of the most authoritative evaluation systems in the AI field [10].
Table: Fundamental Characteristics of Testing Methodologies
| Characteristic | Traditional Proficiency Testing | Blind Testing |
|---|---|---|
| Awareness of Evaluation | Participants know they are being assessed | Evaluators unaware of specific assessment context |
| Sample Identity | Known reference materials with expected values | Anonymous samples without identification |
| Primary Objective | Verify technical competence and method accuracy | Measure real-world performance and user preference |
| Data Output | Quantitative accuracy against reference standard | Qualitative preference and comparative ranking |
| Evaluation Context | Controlled laboratory conditions | Simulated real-world usage scenarios |
| Bias Control | Standardized methods to minimize procedural variation | Anonymous assessment to eliminate brand/preference bias |
Comparative Case Study: AI Model Evaluation
Experimental Protocol and Methodology
The LMArena blind testing platform employs a rigorous experimental protocol designed to eliminate bias while generating robust comparative data. The evaluation process begins with users submitting textual prompts or questions to the platform. The system then processes each query through two different AI models selected randomly from a pool of candidates. Critically, the outputs are presented to users without any identification of the underlying AI systems that generated them [10].
Users then evaluate the anonymous responses based on their subjective preference, considering factors such as accuracy, completeness, clarity, and usefulness. This preference data is aggregated across thousands of independent comparisons to generate a global performance ranking. The platform's authority stems from its massive scale and elimination of brand identification, forcing evaluations based solely on output quality rather than reputation or market presence [10].
In a recent evaluation cycle, the platform assessed 26 competing AI models through this blind comparison methodology. The extensive dataset generated through this process identified Tencent's Hunyuan Image 3.0 as the top-performing model, surpassing established competitors including Seedream 4 and Gemini 2.5 Flash Image Preview [10]. This outcome was particularly noteworthy as it represented the first time an open-source model achieved the top position in these rankings, demonstrating how blind testing can reveal performance advantages that might be obscured in traditional testing environments.
Quantitative Results and Performance Metrics
The blind testing results provided multidimensional insights into model performance that extended beyond simple ranking positions. The evaluation categorized Hunyuan Image 3.0 as the "Best Comprehensive Text-to-Image Model" and "Best Open-Source Text-to-Image Model," indicating strengths across both general performance and specific implementation attributes [10].
Qualitative analysis of the winning model's capabilities revealed several distinctive strengths. The model demonstrated exceptional semantic understanding accuracy, robust commonsense reasoning capabilities, and what evaluators described as "ultimate aesthetic quality" in generated images [10]. Additionally, the system supported both Chinese and English text generation with sophisticated long-text rendering capabilities. These attributes emerged organically through the blind evaluation process rather than being measured against predetermined benchmarks.
Table: Blind Testing Performance Evaluation of AI Models
| Evaluation Metric | Hunyuan Image 3.0 | Seedream 4 | Gemini 2.5 Flash |
|---|---|---|---|
| Overall Ranking | 1st | Outperformed | Outperformed |
| Model Type | Open-source | Not Specified | Proprietary |
| Semantic Understanding | Exceptional accuracy | Not specified | Not specified |
| Aesthetic Quality | Ultimate aesthetic quality | Not specified | Not specified |
| Multilingual Support | Chinese and English | Not specified | Not specified |
| Text Rendering | Advanced long-text capability | Not specified | Not specified |
| Commonsense Reasoning | Strong capabilities | Not specified | Not specified |
Comparative Analysis: Methodological Strengths and Limitations
Bias Elimination and Real-World Predictive Value
The fundamental advantage of blind testing lies in its ability to eliminate multiple forms of assessment bias that can skew results in traditional proficiency testing. By removing brand identification and evaluation context, blind testing forces assessments based solely on performance and output quality. This approach provides superior predictive value for real-world performance where end-users typically engage with products or systems without the awareness that they're participating in an evaluation.
In the AI model assessment case, the blind testing methodology prevented the reputation of established technology providers from influencing results. This allowed a relatively new open-source model to demonstrate its competitive advantages based purely on output quality [10]. The massive scale of the evaluation—with thousands of independent comparisons—provided statistical power that compensated for the inherent subjectivity of individual preference assessments. This combination of bias elimination and large-sample validation creates a compelling argument for blind testing when the primary concern is predicting actual user satisfaction and adoption.
Measurement Precision and Technical Competence Assessment
Traditional proficiency testing excels in its ability to generate precise, quantitative measurements of technical competence against established reference standards. The FDA milk testing program, for instance, provided specific, measurable performance metrics for laboratory analytical capabilities across multiple critical safety parameters [9]. The program's structured approach allowed for direct comparison across laboratories and over time, creating a robust dataset for tracking performance trends and identifying areas needing improvement.
The 2021 review of the FDA proficiency exercises demonstrated the effectiveness of this approach, showing steady improvement in correct results from participating laboratories between 2012 and 2018 [9]. This longitudinal improvement suggests that the iterative feedback loop inherent in traditional proficiency testing—where laboratories receive specific performance data and can implement corrective measures—drives tangible improvements in technical competence. This characteristic makes traditional proficiency testing particularly valuable for regulatory compliance and quality assurance in fields where precise measurement against established standards is paramount.
Implementation Challenges and Resource Requirements
Both methodologies present distinct implementation challenges that influence their appropriateness for specific assessment contexts. Traditional proficiency testing requires sophisticated reference material preparation, standardized distribution protocols, and centralized data analysis capabilities. The suspension of the FDA milk proficiency testing program in 2025 highlights the vulnerability of these complex systems to resource constraints and organizational changes [9]. The program's suspension was directly attributed to "major federal workforce reductions" and the pending closure of the supporting laboratory facility, demonstrating how resource-intensive traditional proficiency testing programs can be [9].
Blind testing implementations face different challenges, particularly regarding scale and evaluation criteria. To generate statistically significant results, blind testing typically requires massive participation volumes—the LMArena platform leverages its global user base to achieve the necessary comparison volume [10]. Additionally, the subjective nature of preference-based evaluation requires careful design to ensure that assessments measure meaningful quality dimensions rather than superficial characteristics. For AI model evaluation, this meant designing interfaces that allowed users to naturally engage with model outputs as they would in real-world usage scenarios, then capturing preference data based on that authentic interaction [10].
The Scientist's Toolkit: Essential Research Reagent Solutions
Table: Key Research Reagent Solutions for Testing and Evaluation
| Reagent/Material | Function in Testing Protocol | Application Context |
|---|---|---|
| Standardized PT Samples | Reference materials with known values for accuracy verification | Traditional proficiency testing programs [9] |
| Bacterial Count Spikes | Milk samples with predetermined bacterial concentrations | SPC, coliform, and PLC proficiency testing [9] |
| Antibiotic Residue Spikes | Samples containing known drug residue concentrations | Appendix N drug residue screening tests [9] |
| Somatic Cell Count Standards | Reference materials with established somatic cell levels | Milk quality assessment in proficiency testing [9] |
| Alkaline Phosphatase Controls | Samples with known enzyme activity levels | Pasteurization verification testing [9] |
| Text Prompt Libraries | Standardized input sets for consistent model evaluation | AI model blind testing platforms [10] |
| Response Comparison Interfaces | Software systems for anonymous output presentation | Blind preference evaluation platforms [10] |
The comparative analysis of blind testing versus traditional proficiency testing reveals complementary rather than competing methodologies. Each approach brings distinctive strengths to the assessment landscape, with optimal application depending on the specific objectives and constraints of the evaluation context.
Traditional proficiency testing remains indispensable for verifying technical competence, ensuring regulatory compliance, and driving continuous improvement in analytical capabilities. The highly structured nature of these programs provides unambiguous performance metrics against established standards, making them particularly valuable in fields where measurement precision directly impacts safety and quality outcomes. The documented improvement in laboratory performance within the FDA milk testing program demonstrates how iterative proficiency testing with structured feedback creates tangible quality enhancements over time [9].
Blind testing emerges as a superior methodology for predicting real-world adoption, user satisfaction, and overall quality perception in competitive environments. By eliminating the biases inherent in branded evaluations, blind testing provides unique insights into how products or systems will perform in authentic usage scenarios. The ability of blind testing to identify unexpected performance advantages—such as the top ranking of an open-source AI model against established proprietary competitors [10]—demonstrates its value for strategic decision-making and product development.
For research and quality assurance professionals, the most effective approach involves strategically combining these methodologies to leverage their complementary advantages. Traditional proficiency testing ensures technical excellence and compliance with established standards, while blind testing validates user-centric quality attributes and predicts market acceptance. As assessment methodologies continue to evolve, this integrated framework will provide the most comprehensive understanding of performance across both technical and user-experience dimensions.
Proficiency testing (PT) serves as a critical component of external quality assurance, enabling laboratories to validate their testing accuracy and demonstrate competency to accreditation bodies and regulators. In clinical diagnostics, the Clinical Laboratory Improvement Amendments (CLIA) establish the foundational requirements for laboratory testing, including mandatory participation in proficiency testing for regulated analytes. The recent updates to CLIA regulations, implemented in January 2025, represent the most significant changes in decades, tightening acceptance limits for numerous analytes to reflect advancing analytical capabilities and clinical needs.
Within this regulatory framework, two distinct methodological approaches have emerged for assessing laboratory performance: traditional declared proficiency testing and blind proficiency testing. While both methods serve quality assessment purposes, they differ fundamentally in design, implementation, and ability to reflect real-world laboratory performance. This guide provides a comparative analysis of these approaches, examining their respective advantages, limitations, and applications within modern laboratory medicine amidst evolving regulatory standards.
CLIA 2025 Updates: Key Changes and Implications
The updated CLIA regulations, formalized through CMS-3355-F, introduce significant modifications to proficiency testing requirements that laboratories must incorporate into their quality assurance programs. These changes, which became fully implemented on January 1, 2025, include tighter performance standards for many established analytes and the addition of new regulated tests.
Major Changes in Acceptance Criteria
The following tables summarize key changes in acceptable performance criteria across different testing specialties:
Table: Selected CLIA 2025 Changes in Chemistry and Toxicology
| Analyte or Test | OLD Acceptance Criteria | NEW 2025 Acceptance Criteria |
|---|---|---|
| Alanine aminotransferase (ALT) | Target value ± 20% | Target value ± 15% or ± 6 U/L (greater) |
| Glucose | Target value ± 6 mg/dL or ± 10% (greater) | Target value ± 6 mg/dL or ± 8% (greater) |
| Creatinine | Target value ± 0.3 mg/dL or ± 15% (greater) | Target value ± 0.2 mg/dL or ± 10% (greater) |
| Hemoglobin A1c | Not previously regulated | Target value ± 8% |
| Blood Alcohol | Target value ± 25% | Target value ± 20% |
| Blood Lead | Target value ± 10% or ± 4 mcg/dL (greater) | Target value ± 10% or ± 2 mcg/dL (greater) |
| Troponin I | Not previously regulated | Target value ± 0.9 ng/mL or ± 30% (greater) |
| Troponin T | Not previously regulated | Target value ± 0.2 ng/mL or ± 30% (greater) |
Table: Selected CLIA 2025 Changes in Hematology and Immunology
| Analyte or Test | OLD Acceptance Criteria | NEW 2025 Acceptance Criteria |
|---|---|---|
| Hematocrit | Target value ± 6% | Target value ± 4% |
| Hemoglobin | Target value ± 7% | Target value ± 4% |
| Leukocyte count | Target value ± 15% | Target value ± 10% |
| Unexpected antibody detection | 80% accuracy | 100% accuracy |
| Complement C3 | Target value ± 3 SD | Target value ± 15% |
| IgA, IgE, IgG, IgM | Target value ± 3 SD | Target value ± 20% |
Implications for Laboratory Operations
These updated requirements reflect several important trends in laboratory medicine. The tighter acceptance limits for many established analytes demonstrate increasing expectations for analytical precision, driven by technological advancements in instrumentation and reagents. The addition of new regulated analytes, including hemoglobin A1c, troponins, and various endocrinology tests, expands the scope of quality monitoring to reflect evolving clinical practice guidelines and the growing importance of these markers in diagnostic and therapeutic decisions.
Furthermore, the shift from standard deviation-based criteria to percentage-based criteria for immunology tests (e.g., Complement C3, immunoglobulins) represents a move toward more consistent evaluation methods across different concentration levels. Laboratories must review their method verification data, establish new baseline performance metrics, and potentially enhance quality control procedures to meet these updated standards consistently.
Comparative Methodologies: Blind vs. Traditional Proficiency Testing
Traditional Declared Proficiency Testing
Traditional proficiency testing, the most widely implemented approach in accredited laboratories, involves the scheduled distribution of known test samples to participating laboratories. These samples are clearly identified as part of a proficiency testing program, and personnel are aware they are being evaluated when processing these specimens.
Key Characteristics:
- Scheduled distribution at regular intervals (typically 3 times annually)
- Overt identification as proficiency testing materials
- Predictable timing and sample type expectations
- Standardized grading against peer group performance
- Educational focus with detailed performance reports
This approach allows laboratories to prepare specifically for proficiency testing events, often assigning their most experienced personnel and applying special quality checks to ensure optimal performance. While this provides valuable educational benefits and helps identify methodological limitations, it may not accurately reflect routine laboratory operations [3].
Blind Proficiency Testing
Blind proficiency testing involves the submission of test samples that mimic routine patient specimens, with laboratory personnel unaware they are being evaluated. This approach, while logistically challenging, provides a more authentic assessment of routine laboratory performance.
Key Characteristics:
- Covert submission disguised as routine patient specimens
- Unpredictable timing and sample characteristics
- Testing of entire laboratory pipeline from receipt to reporting
- Assessment of routine performance without special preparation
- Potential to detect misconduct or systematic procedural deviations
Blind PT programs are more established in federal forensic facilities and certain medical testing industries, but remain underrepresented in clinical laboratory practice despite their significant advantages for quality assessment [3].
Experimental Comparison: Methodologies and Outcomes
Historical Case Study Design
A seminal 1977 study provides compelling experimental data comparing laboratory performance with blind and traditional proficiency testing methodologies [11]. The investigation employed a rigorous paired-comparison design:
Experimental Protocol:
- Sample Preparation: Identical simulated addict urine samples containing drugs were prepared for distribution
- Dual Distribution Mechanism:
- Blind testing arm: Samples were sent to collaborating hospital administrators and methadone center officials, who forwarded them to their supporting laboratories as ordinary patient specimens
- Traditional testing arm: The identical samples were mailed directly to the same laboratories as part of a regular CDC proficiency testing program
- Participating Laboratories: Multiple laboratories already participating in the CDC proficiency testing program
- Performance Evaluation: Comparison of testing accuracy between the two distribution methods for identical samples
Table: Experimental Design of 1977 Proficiency Testing Comparison
| Experimental Component | Blind Testing Arm | Traditional Testing Arm |
|---|---|---|
| Sample Composition | Identical simulated addict urine samples with drugs | Identical simulated addict urine samples with drugs |
| Sample Identification | Presented as routine patient specimens | Identified as proficiency testing materials |
| Distribution Pathway | Via hospital administrators and methadone center officials | Direct mail from CDC proficiency testing program |
| Laboratory Awareness | Unaware of testing situation | Aware of proficiency testing evaluation |
| Performance Metric | Testing accuracy for drug detection | Testing accuracy for drug detection |
Comparative Results and Implications
The findings revealed significant disparities in laboratory performance between the two testing approaches:
Performance Outcomes:
- Most laboratories performed acceptably with the traditionally distributed proficiency testing samples
- Many of these same laboratories performed poorly when analyzing the identical samples submitted as blind specimens
- The performance gap demonstrated that awareness of testing conditions substantially influenced laboratory operations and results quality
This study highlighted fundamental limitations of traditional proficiency testing alone and prompted recommendations for complementary monitoring approaches, including onsite performance evaluation programs to provide more comprehensive quality assessment [11].
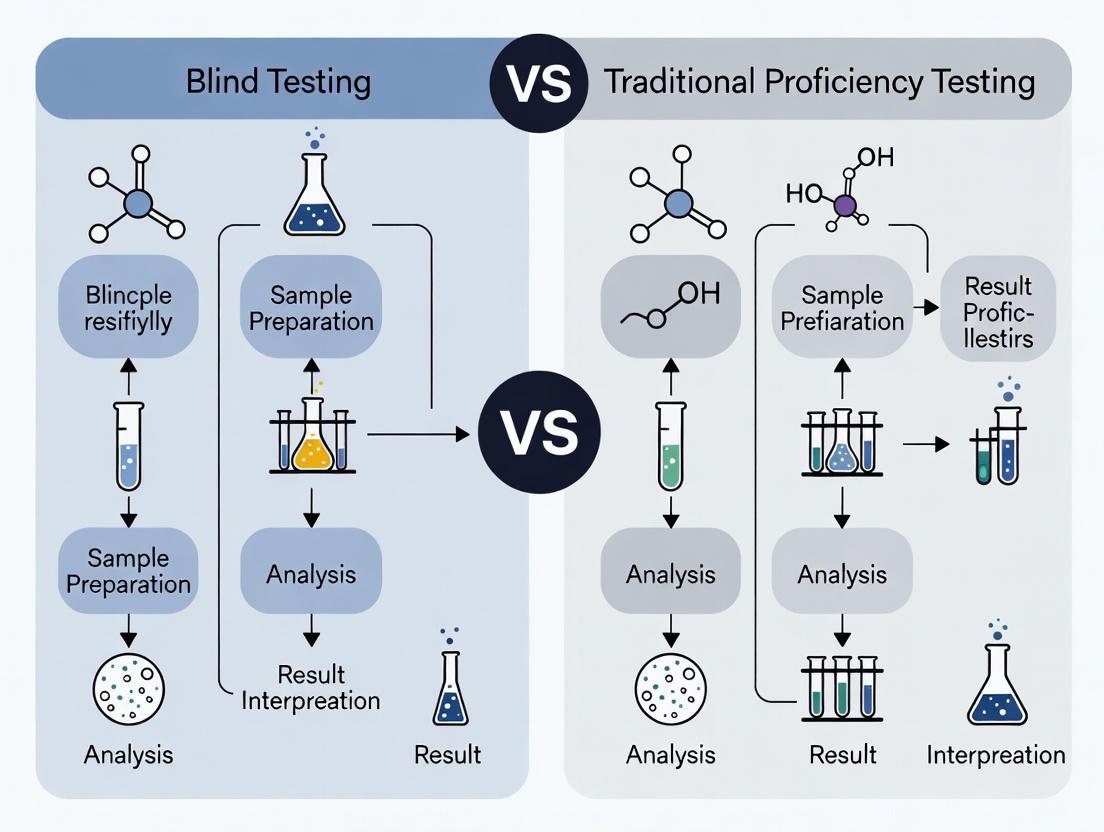
Visualizing Proficiency Testing Methodologies
Diagram: Proficiency Testing Methodologies Comparison
This workflow illustrates the fundamental differences between traditional and blind proficiency testing approaches. The divergence at the distribution phase creates fundamentally different testing conditions, with traditional PT triggering special handling protocols while blind PT maintains normal operational conditions, resulting in potentially different performance outcomes.
Implementation Considerations and Industry Outlook
Barriers to Blind Proficiency Testing Adoption
Despite its theoretical advantages, blind proficiency testing faces significant implementation challenges in clinical laboratory settings:
Logistical Constraints:
- Sample authenticity: Creating blind samples that perfectly mimic patient specimens across all test modalities
- Regulatory compliance: Navigating CLIA requirements while maintaining blinding integrity
- Result reconciliation: Managing clinical reporting obligations for disguised specimens
- Program administration: Higher complexity and cost compared to traditional PT programs
Cultural and Operational Barriers:
- Resource intensiveness: Requires significant coordination with clinical partners for sample submission
- Resistance to change: Laboratories may perceive blind testing as unfairly punitive rather than educational
- Accreditation frameworks: Traditional PT is deeply embedded in current quality assurance paradigms [3]
The Evolving Proficiency Testing Market
The global proficiency testing market reflects growing emphasis on laboratory quality standards, with the market valued at approximately $1.2 billion in 2023 and projected to reach $1.6 billion by 2028 [12]. Key providers driving innovation include:
Table: Leading Proficiency Testing Providers and Specializations
| Provider | Specializations | Global Reach |
|---|---|---|
| LGC Limited (UK) | Clinical, food, environmental, pharmaceutical | ~19% market share; 13,000+ labs in 160+ countries |
| College of American Pathologists (US) | Clinical laboratory medicine | 25,000+ participating laboratories worldwide |
| Bio-Rad Laboratories (US) | Clinical chemistry, immunoassays, hematology | ~14% market share; 150+ countries |
| Randox Laboratories (UK) | RIQAS - clinical chemistry, hematology, immunoassay | 70,000+ participants across 140 countries |
| Fera Science (UK) | FAPAS - food, water, environmental | Thousands of labs in 130+ countries |
These organizations are increasingly incorporating technological innovations, including AI-driven result analysis and expanded test menus for emerging diagnostics, to enhance the value and efficiency of proficiency testing programs [12].
Essential Research Reagent Solutions for Proficiency Testing
Implementing robust proficiency testing programs requires specific materials and reagents to ensure accurate, reproducible results. The following solutions are fundamental to both traditional and blind PT methodologies:
Table: Essential Research Reagent Solutions for Proficiency Testing
| Reagent Category | Specific Examples | Primary Function in PT |
|---|---|---|
| Matrix-Matched Materials | Synthetic urine, artificial serum, lyophilized blood | Provides physiologically relevant sample matrices that mimic patient specimens for realistic testing conditions |
| Stable Analyte Solutions | Certified reference materials, spiked solutions | Delivers known analyte concentrations at critical decision levels for accurate performance assessment |
| Preservation and Stabilization Reagents | Antimicrobial agents, enzyme inhibitors, stabilizers | Maintains sample integrity during shipping and storage, preventing analyte degradation |
| Interference Testing Panels | Hemolyzed, icteric, lipemic samples | Evaluates method specificity and identifies potential interferents affecting accuracy |
| Calibration Verification Materials | Standards traceable to reference methods | Ensures analytical measurement continuity and standardization across testing events |
These reagent systems must demonstrate commutability with patient samples (reacting similarly in analytical systems), long-term stability throughout PT event cycles, and concentration accuracy at clinically relevant decision points to provide meaningful performance assessment.
The evolving regulatory landscape, exemplified by the CLIA 2025 updates, reflects increasing expectations for analytical quality in laboratory medicine. While traditional proficiency testing remains a foundational component of quality assurance programs, evidence suggests that supplementing with blind testing methodologies could provide more authentic assessment of routine laboratory performance.
The comparative analysis presented demonstrates that methodology significantly influences performance outcomes, with laboratories typically demonstrating better results under declared testing conditions. As the proficiency testing industry continues evolving, incorporating technological innovations and complementary assessment approaches will be essential for advancing quality standards.
For researchers, scientists, and drug development professionals, understanding these methodological distinctions is crucial when evaluating laboratory performance data or designing quality assessment protocols. A balanced approach incorporating both traditional educational PT and periodic blind assessment may offer the most comprehensive evaluation of laboratory competency, ultimately supporting improved patient care through enhanced diagnostic accuracy.
盲测试 vs 传统能力验证:质量保证与性能验证的双重路径
方法论基础与核心目标
在科学研究与产品开发,尤其是药物研发领域,质量保证和性能验证是确保结果可靠性的基石。盲测试与传统能力验证作为两种核心实验方法,虽共享确保数据准确性的终极目标,但其哲学基础、实施路径和适用场景存在系统性差异。
盲测试,尤其在在线对照实验中,通过将受试单元随机分配至实验组和对照组,并在不知情条件下施加不同干预,以验证因果关系。该方法源自生物医学的“双盲测试”,随机化过程能有效控制除干预策略外的混杂变量,确保结果差异可归因于干预本身。在理想情况下,它通过创建可比较的组群来近似“平行时空”,从而定量评估策略收益、风险和成本 [13]。
传统能力验证则是一种外部质量评估程序,通过实验室间比对来确定实验室从事特定测试的能力。它作为临床实验室改进修正案的核心组成部分,通过向参与实验室分发已知样本,将其检测结果与参考值或同行结果进行比较,从而评估并证明其检测系统的准确性。2024年美国医疗保险和医疗补助服务中心的新规将其更新为包含更多分析物、更多挑战次数和更严格的评分标准,以符合现代医学实践需求 [14]。
关键参数的系统比较
下面的综合对比表格详细列出了两种方法在核心参数上的差异,为研究人员的方法选择提供依据。
表:盲测试与传统能力验证的关键参数比较
| 比较维度 | 盲测试 | 传统能力验证 |
|---|---|---|
| 核心目标 | 验证因果关系;定量评估干预效果 | 评估实验室检测准确性;确保结果可比性 |
| 方法论基础 | 随机分组;对照原则;假设检验 | 样本循环;实验室间比对;一致性评估 |
| 随机化应用 | 核心要素,通过随机分配消除混杂偏倚 | 通常不涉及,主要依赖既定检测流程 |
| 实施频率 | 按需进行,与产品迭代或策略变更同步 | 定期进行,通常每年3次挑战 [14] |
| 样本类型 | 真实用户、实验动物或模拟案例 | 已知特性的标准物质或临床样本 |
| 结果评估 | 统计显著性检验;效应值计算 | 与靶值或共识值的偏差分析;通过/失败判定 |
| 主要输出 | 因果关系的定性结论与效果大小的定量估计 | 检测准确性的客观证据;实验室能力证明 |
| 监管地位 | 多数情况下为内部决策工具 | CLIA等法规的明确要求;实验室认证必备 [14] |
| 适用领域 | 药物疗效试验、产品特性评估、用户体验优化 | 临床诊断、环境监测、法医学检测 |
| 典型分析单元 | 用户行为指标、临床终点事件、产品使用数据 | 分析物浓度、微生物鉴定、基因序列 [15] |
能力验证的评分标准近年来持续进化。以临床化学为例,新规将许多分析物的可接受性能界限从标准差改为百分比基础限值,或结合绝对值与百分比中更宽容者。例如,胆红素的性能要求为±20%或±0.4 mg/dL,甲状腺刺激激素为±20%或±0.2 mIU/L,锂为±15%或±0.3 mmol/L [14]。
实验方案与工作流程
盲测试的标准实施流程
规范的盲测试流程包括实验设计、随机分组、干预实施、数据收集和统计分析等关键阶段。下面的流程图详细描述了这一标准化过程。
传统能力验证的执行路径
传统能力验证遵循样本准备、分发、检测、结果报告和性能评估的系统流程,其标准操作流程如下:
研究试剂与关键材料
在两种方法中,一系列标准化的试剂和材料对保证实验质量至关重要。以下表格列出了关键研究试剂解决方案及其功能。
表:质量验证研究中的关键试剂与材料
| 试剂/材料类别 | 主要功能 | 应用场景 |
|---|---|---|
| 认证参考物质 | 提供可溯源的定量标准 | 能力验证样本制备;方法校准 |
| 稳定化临床样本 | 模拟真实患者样本的基质效应 | 能力验证;检测方法验证 |
| 冻干质控品 | 长期稳定性,便于运输 | 实验室内部质量控制;能力验证 |
| 分析物特异性试剂 | 确保检测方法特异性 | 方法开发与验证;盲测试终点检测 |
| 标准化培养基 | 提供微生物一致性生长环境 | 微生物学能力验证;盲测试 |
| DNA提取与纯化试剂盒 | 保证核酸质量与一致性 | 分子诊断能力验证 [15] |
| PCR主混合物 | 提供扩增反应稳定性 | 核酸检测盲测试;分子方法验证 |
| 校准品套装 | 建立检测标准曲线 | 方法标准化;设备校准 |
能力验证样本的制备需满足一致性、稳定性和互换性要求。新规要求每年进行三次能力验证挑战,每次包含五个样本,较之前的两挑战有所增加,以提高评估可靠性 [14]。在微生物能力验证中,混合培养要求已从50%降至25%,适应了临床样本的真实复杂性 [14]。
应用场景与典型案例
盲测试的典型应用场景
盲测试在多个领域具有广泛应用,尤其在需要确立因果关系的场景中表现卓越:
- 药物临床试验:通过随机双盲对照研究,评估新药疗效与安全性,是药品注册的黄金标准。
- 产品策略优化:如美团在评估新补贴策略时,通过随机将用户分为实验组和对照组,量化策略对下单规模的影响 [13]。
- 界面与用户体验测试:在A/B测试中比较不同设计对用户行为的影响,如验证App弹窗和标签展示对用户下单意愿的促进效果 [13]。
- 算法性能评估:在相同数据集上盲测不同算法,避免主观偏见影响性能评估。
传统能力验证的核心应用领域
传统能力验证在确保实验室检测质量方面发挥着不可或缺的作用:
- 临床实验室检测:如心脏肌钙蛋白和HbA1c等关键指标的性能验证,新规已将这些现代医学重要指标纳入必需的能力验证项目 [14]。
- 微生物鉴定与药敏试验:通过样本循环确保菌种鉴定和药物敏感性检测的准确性。
- 分子诊断检测:如DNA测序流程的验证,确保分子生物监测结果的可重复性 [15]。
- 法医学检测:通过实验室间比对确保检测结果的可比性与可靠性。
- 环境监测:如通过水质、空气样本分析验证检测能力。
方法选择与整合策略
面对两种方法的选择,研究人员需考虑研究目标、资源约束和监管要求。盲测试更适合因果推断和策略效果评估,而传统能力验证则是实验室质量保证和法规符合性的必备要素。
在实际研究中,两种方法可协同应用。例如,在评估新检测方法时,可先通过盲测试确定其诊断性能,再通过能力验证确认其在常规实验室条件下的稳健性。能力验证的新规指南强调,实验室不应仅将可接受限作为性能目标,而应将其视为最低标准,并在此基础上追求更优的质量目标 [14]。
在面临小样本或溢出效应等复杂情况时,如美团履约业务中的区域策略测试,需要设计更精细的实验方案,如采用随机轮转实验或准实验设计来克服传统方法的局限 [13]。这些创新方法扩展了质量验证方法学的边界,为复杂场景下的性能验证提供了新思路。
两种方法共同构成了科学研究与专业实践中的质量保证体系,通过不同的路径确保了从实验室发现到产品应用全链条的可靠性与可信度。
From Theory to Practice: Implementing Testing Strategies in Research and Diagnostics
This guide provides a comparative analysis of traditional (declared) proficiency testing (PT) and blind proficiency testing, two critical methodologies for ensuring quality in forensic laboratories. For researchers and drug development professionals, understanding the structures, workflows, and comparative effectiveness of these approaches is essential for implementing robust quality assurance systems. Traditional PT, while established and logistically simpler, exhibits significant limitations in ecological validity compared to blind PT, which tests the entire laboratory pipeline under realistic conditions. The data and workflows presented herein stem from current practices and research within forensic science, offering a framework for evaluating these complementary quality assessment tools.
Understanding Proficiency Testing Modalities
Proficiency testing (PT) is a mandatory quality assurance component for accredited forensic laboratories, designed to monitor and validate the performance of examiners and analytical processes [3] [16]. The execution and ecological validity of PT, however, differ substantially based on whether the testing is declared or blind.
Traditional (Declared) Proficiency Testing: In this common model, examiners are aware that they are being evaluated. Known samples are submitted explicitly as a test, and examiners typically process them outside the normal casework flow. This approach helps identify gross technical errors but fails to assess the full laboratory ecosystem.
Blind Proficiency Testing: This method involves submitting known samples to the laboratory disguised as regular casework [17]. The goal is to test the entire laboratory pipeline—from evidence intake and assignment to analysis and reporting—without altering examiner behavior due to the awareness of being assessed [3]. It is one of the only methods capable of detecting systemic issues and misconduct [3].
The core distinction lies in behavioral fidelity. As noted by researchers, when examiners know they are being tested, they "will possibly behave differently than they do in everyday casework" [17]. Blind testing eliminates this "observer effect," providing a more authentic measure of a laboratory's operational performance [3].
Comparative Analysis: Blind vs. Traditional PT
The table below summarizes the key characteristics and comparative performance of traditional and blind proficiency testing models based on current implementations in forensic laboratories.
Table 1: Comparative Analysis of Traditional vs. Blind Proficiency Testing
| Feature | Traditional (Declared) PT | Blind PT |
|---|---|---|
| Primary Objective | Technical competency check of individual examiners [3] | Assessment of the entire laboratory pipeline and operational performance [3] [17] |
| Ecological Validity | Low; does not mimic real casework pressure and workflow [3] | High; designed to resemble actual cases [3] |
| Examiner Behavior | Potentially altered (Hawthorne Effect) [17] | Reflects normal, real-world behavior [3] |
| Error Rate Estimation | Provides limited, potentially optimistic error rates | Offers realistic preliminary data on performance in casework-like situations [17] |
| Misconduct Detection | Limited capability | One of the only reliable methods for detection [3] |
| Logistical Complexity | Low; easily integrated into quality manual protocols | High; requires careful planning and resources to mimic casework [3] [16] |
| Current Adoption | Majority of forensic laboratories [3] [16] | Limited, primarily in some federal facilities; growing interest [3] [17] |
Workflow Breakdown: A Step-by-Step Guide
The execution of traditional and blind PT programs follows distinct workflows. The following diagrams and breakdowns illustrate the procedural steps for each.
Traditional (Declared) PT Workflow
The traditional PT process is a linear, controlled sequence managed within the laboratory's quality assurance framework.
Diagram 1: Traditional declared PT follows a linear, controlled path.
- Step 1: Program Initiation & Sample Receipt: The Quality Assurance (QA) Manager receives a known proficiency test sample from an external provider or an internal source. The sample is explicitly logged as a PT sample.
- Step 2: Declared Assignment: The QA manager assigns the PT sample to an examiner or a team. The assignment explicitly communicates that the task is a proficiency test, not actual casework.
- Step 3: Examiner Analysis: The examiner analyzes the sample following standard operating procedures. Critically, their behavior may be altered because they know they are being evaluated (e.g., increased caution, repetition, consultation) [17].
- Step 4: Result Submission & Scoring: The examiner submits their findings to the QA manager or the external PT provider. The results are scored against the known ground truth.
- Step 5: Performance Review: The scores are reviewed. Satisfactory performance is documented. Unsatisfactory results trigger a predefined corrective action process, which may include retraining and re-testing.
Blind PT Workflow
The blind PT workflow is a cyclical, integrated process designed to inject test samples seamlessly into the regular casework stream, testing the system from intake to final report.
Diagram 2: Blind PT integrates test samples secretly into the casework flow.
- Step 1: Covert Sample Introduction: A blind proficiency test sample, designed to closely resemble actual casework, is submitted to the laboratory through its standard intake channels [3]. This is often orchestrated by researchers or a dedicated internal team in collaboration with external partners [17].
- Step 2: Evidence Intake & Assignment: The evidence receiving unit processes the sample according to standard protocols, logging it as a regular case. It is then assigned to an examiner through the normal workflow management system, with no indication it is a test.
- Step 3: Unaware Examiner Analysis: The examiner analyzes the sample as they would any other case, with no behavioral changes due to test awareness [3]. This step tests the entire analytical pipeline under realistic conditions.
- Step 4: Normal Result Reporting: The examiner completes their analysis and generates a final report, which is submitted through the standard chain of command.
- Step 5: Reveal & Systemic Debrief: Once the final report is issued, the test is revealed. Laboratory leadership and researchers then conduct a comprehensive debriefing. This analyzes not just the accuracy of the result, but also the entire process, "from workflow to customer service," to identify systemic strengths and weaknesses [17].
Experimental Protocols & Key Methodologies
Implementing a robust blind PT program requires meticulous experimental design. The following protocol is synthesized from successful implementations discussed in forensic science workshops and literature [17] [16].
Protocol for Implementing a Blind Proficiency Test
- Objective: To assess the accuracy, efficiency, and adherence to protocol of the laboratory's casework pipeline under realistic operating conditions.
- Hypothesis: The laboratory's error rate and procedural compliance in blind testing will be consistent with (or provide a more valid measure than) rates derived from declared PT.
- Materials: See "The Scientist's Toolkit" below for specific reagent solutions and materials. The core material is a pre-validated, stable test sample with a ground-truth value known only to the test administrators.
- Methodology:
- Sample Design & Validation: Develop or source a test sample that is forensically realistic and forensically relevant. It must be stable, safe to handle, and its "ground truth" must be unequivocally known and pre-validated by a reference method.
- Blinding Procedure: A dedicated "blinding team" (which may include external researchers) prepares the sample for submission. This includes creating a plausible, fictional scenario or donor information and using standard evidence packaging.
- Submission and Monitoring: The blinding team submits the sample to the laboratory's standard evidence intake. The case progress is monitored discreetly through the laboratory's case management system, if possible, without alerting staff.
- Data Collection: Data points collected include: the analysis result, the time-to-completion, all case notes, procedures used, any chain-of-custody documentation, and the final report.
- Reveal and Analysis: After the final report is issued, the test is revealed. The result is compared to the ground truth. The process is reviewed not just for accuracy, but for all aspects of laboratory function.
The Scientist's Toolkit
Implementing proficiency testing, particularly the blind model, requires both conceptual and material resources. The table below details essential components for establishing a proficient testing program.
Table 2: Key Research Reagent Solutions for Proficiency Testing
| Item / Solution | Function in PT Execution |
|---|---|
| Pre-Validated Reference Materials | Serve as the ground-truth sample for blind or declared PT. Their known composition is the benchmark against which examiner performance is measured. |
| Realistic Matrix Blanks | Provides the substrate (e.g., synthetic sweat, inert cloth, mock biological tissue) for the reference material, ensuring the test sample mimics real evidence. |
| Secure Case Management System | The software platform for tracking the blind PT case through the laboratory's normal workflow, allowing for discreet monitoring by administrators. |
| Standard Evidence Packaging | Used to present the blind PT sample identically to real case evidence, maintaining the deception necessary for ecological validity. |
| Statistical Analysis Package | Software used to analyze results, calculate error rates, and determine the statistical significance of performance data from multiple PT rounds. |
| Corrective Action Protocol | A predefined, documented process for addressing unsatisfactory PT results, which is a critical component of a closed-loop quality system. |
The comparative analysis reveals that traditional declared PT and blind PT are not mutually exclusive but serve complementary roles in a comprehensive quality assurance program [17]. Traditional PT remains a logistically straightforward tool for mandatory competency checks and foundational skill assessment. However, its limitation in ecological validity is a significant shortcoming. Blind PT, while resource-intensive to implement, provides unparalleled insights into the true operational health of a forensic laboratory, testing the entire system from intake to reporting and capturing realistic error rates [3] [17].
The primary obstacles to blind PT are logistical and cultural, including the difficulty of designing realistic cases and integrating them seamlessly into workflow, as well as potential resistance from within the laboratory culture [3] [16]. However, the trend is toward greater adoption. As noted by Dr. Jeff Salyards, "The future is bright as more and more laboratory leaders see value of blind proficiency testing" [17]. For researchers and professionals committed to rigorous quality assessment, a dual-strategy approach—using declared PT for fundamental competency and blind PT for systemic validation—represents the current state-of-the-art in ensuring the reliability and integrity of forensic and analytical sciences.
Blind testing serves as a critical methodology in comparative analysis, providing a mechanism for objectively evaluating product performance while minimizing bias. Unlike traditional proficiency testing, which may involve open assessments where participants know they are being evaluated, blind testing conceals the test's identity from participants, ensuring they perform as they would under normal conditions [18]. This approach is particularly valuable in scientific fields and drug development, where it helps generate unbiased data on error rates, accuracy, repeatability, and reproducibility of methods and instruments [19].
Framed within a broader thesis on comparative analysis, this guide explores how blind testing offers distinct advantages over traditional proficiency testing by more accurately simulating real-world conditions and providing less biased performance metrics. Where traditional proficiency testing often follows established protocols with known samples, blind testing introduces an element of realism that can better reveal true performance characteristics under operational conditions [18]. This objective comparison is essential for researchers, scientists, and drug development professionals who rely on accurate performance data to make informed decisions about methodologies, instruments, and technologies.
Key Concepts and Definitions
Fundamental Terminology
- Blind Test: A controlled assessment where the examiner or participant is unaware they are being tested, ensuring performance reflects normal operational conditions [18]. The test source or purpose is concealed until after completion.
- Proficiency Testing (PT): The determination of calibration or testing performance of a laboratory or inspection body against pre-established criteria through interlaboratory comparisons [18].
- Interlaboratory Comparisons (ILC): The organization, performance, and evaluation of tests on the same or similar items by two or more laboratories in accordance with predetermined conditions [18].
- Internal Validity: The extent to which study results are trustworthy and free from biases, ensuring observed effects truly result from the variables being studied rather than external factors [20].
- External Validity: The extent to which research findings can be generalized or applied to situations, settings, populations, or times outside the study itself [20].
Experimental Design and Methodologies
Core Blind Test Design Principles
Effective blind testing requires meticulous planning across several key dimensions. The sample design must incorporate appropriate challenge levels that reflect real-world scenarios while controlling for variables that could confound results. Participant selection should represent the target user population, with sample sizes determined by statistical power requirements rather than convenience [21].
Three primary design architectures dominate blind testing methodologies:
- Full Blind Design: Participants are completely unaware of their involvement in a test, with test materials integrated seamlessly into normal workflow [18].
- Single-Blind Design: Participants know they are being tested but lack critical information about expected outcomes or sample origins.
- Double-Blind Design: Neither participants nor administrators know critical test parameters until after evaluation, minimizing unconscious influence on results [19].
The selection of appropriate positive and negative controls is paramount, as these determine the test's ability to accurately classify performance. Positive controls should represent known functioning systems, while negative controls should include samples with confirmed absence of the target characteristic or effect.
Quantitative Research Designs Hierarchy
The hierarchy of evidence provides a framework for evaluating research design strength, with blind testing occupying the higher tiers due to its robust controls against bias [20].
Figure 1: Evidence Hierarchy in Research Design
Logistics Framework Implementation
Sample Design and Distribution Logistics
Implementing a successful blind test requires meticulous logistical planning, particularly regarding sample design and distribution. The sample matrix must represent the full spectrum of challenges encountered in real-world applications, including edge cases and potential interferents. For drug development studies, this includes varying concentrations, matrices, and stability conditions.
Distribution logistics must maintain the blind nature of the study while ensuring sample integrity. For physical samples, this requires standardized packaging, shipping conditions, and chain-of-custody documentation. Electronic sample distribution offers advantages for data integrity but requires secure, validated systems to prevent technical artifacts from influencing results [18].
The following workflow illustrates a comprehensive blind testing implementation process:
Figure 2: Blind Test Implementation Workflow
Data Collection and Management
Data collection in blind testing must balance comprehensive information gathering with the need to maintain blinding. Standardized data collection forms (either electronic or paper-based) should capture all relevant variables without revealing test parameters. For comparative studies, this includes:
- Raw instrument outputs and calculated results
- Environmental conditions during testing
- Operator information and experience level
- Time stamps for each testing phase
- Any deviations from standard protocols
Data management systems must ensure confidentiality while allowing for appropriate aggregation and analysis. Automated data validation checks should flag outliers or missing values without revealing expected results to maintain blinding.
Comparative Analysis: Blind Testing vs Traditional Proficiency Testing
Methodological Comparison
Blind testing and traditional proficiency testing represent complementary but distinct approaches to performance assessment. Understanding their relative strengths and limitations enables researchers to select the most appropriate methodology for their specific comparative analysis needs.
Table 1: Methodological Comparison of Testing Approaches
| Characteristic | Blind Testing | Traditional Proficiency Testing |
|---|---|---|
| Participant Awareness | Unaware of being tested [18] | Aware of evaluation [18] |
| Sample Origin | Concealed until after assessment [18] | Often known or suspected |
| Performance Realism | High (simulates real conditions) [18] | Variable (potential for optimized performance) |
| Error Rate Detection | More accurate representation of operational errors [18] | May underestimate true error rates |
| Implementation Complexity | High (requires deception infrastructure) | Moderate (standardized protocols) |
| Cost Considerations | Generally higher due to complexity | Typically lower |
| Regulatory Acceptance | Growing recognition as superior method | Well-established in many industries |
Performance Metrics and Outcomes
Quantitative comparison of error rates between blind and traditional proficiency testing reveals significant differences in performance assessment accuracy across multiple studies.
Table 2: Performance Metrics Comparison
| Performance Metric | Blind Testing Results | Traditional Proficiency Testing Results |
|---|---|---|
| False Positive Rate | Higher, more accurate reflection of operational performance [18] | Often lower due to heightened participant caution |
| False Negative Rate | More representative of real-world conditions [18] | May be underestimated |
| Inter-laboratory Variability | Better identification of true methodological differences [18] | May be masked by optimized performance |
| Repeatability | Accurate assessment under normal conditions [19] | Potentially inflated |
| Reproducibility | Realistic measure across different operators [19] | May not reflect daily performance |
The Scientist's Toolkit: Essential Research Reagents and Materials
Core Research Materials
Table 3: Essential Research Reagents and Solutions
| Item | Function/Purpose | Application Context |
|---|---|---|
| Reference Standards | Certified materials with known properties for instrument calibration and method validation | Quality control, assay calibration, method verification |
| Internal Controls | Samples with predetermined results for monitoring assay performance | Process control, error detection, validity determination |
| Matrix-Matched Samples | Test materials in appropriate biological or chemical matrices | Simulation of real-world conditions, interference assessment |
| Blinded Sample Panels | Curated sample sets with concealed identities | Performance assessment, bias minimization, competency evaluation |
| Stability Materials | Samples for evaluating stability under various conditions | Shelf-life determination, storage condition optimization |
Regulatory Considerations and Compliance
Recent regulatory changes have heightened requirements for robust testing methodologies across industries. In clinical laboratories, updated CLIA regulations effective January 2025 require more frequent proficiency testing challenges—increasing from two to three challenges annually with five samples per challenge rather than fewer samples [14]. This reflects a growing recognition of the importance of comprehensive performance assessment.
Both blind testing and traditional proficiency testing must address regulatory compliance requirements, though their paths may differ. Traditional proficiency testing often follows prescribed protocols with established acceptance criteria, such as the percentage-based limits now implemented under updated CLIA rules where, for example, bilirubin testing must achieve ±20% or ±0.4 mg/dL, and thyroid stimulating hormone must meet ±20% or ±0.2 mIU/L [14]. Blind testing methodologies, while potentially providing superior performance assessment, may require additional validation to demonstrate equivalence to regulatory standards.
Blind testing represents a sophisticated methodology for comparative analysis that provides distinct advantages over traditional proficiency testing in assessing true operational performance. By concealing the testing nature from participants, blind testing generates more accurate error rate data, identifies operational weaknesses, and provides a realistic assessment of method performance under normal working conditions [18].
The future of blind testing in research and drug development will likely see increased adoption as regulatory bodies recognize its superior ability to assess true operational performance. Emerging trends include virtual blind testing platforms, AI-assisted result analysis, and integrated testing frameworks that combine blind and traditional approaches for comprehensive performance assessment.
For researchers designing comparative studies, the methodological framework presented here provides a foundation for implementing robust blind testing protocols that yield meaningful, actionable data for product development and method validation. As the scientific community continues to prioritize data quality and reproducibility, blind testing methodologies will play an increasingly central role in evidence generation across diverse scientific disciplines.
Detection bias is a systematic error that occurs in clinical trials when the knowledge of a patient's assigned treatment influences how outcomes are ascertained or measured [22]. This bias is a paramount concern in unblinded pragmatic trials and observational studies, where patients, healthcare providers, or outcome assessors are aware of the treatment assignment. Such knowledge can consciously or subconsciously affect behaviors; for instance, patients might report symptoms differently, clinicians might monitor more closely, or outcome assessors might interpret ambiguous data favorably towards the expected treatment effect [22] [23]. The direction of this bias is often towards exaggerating the perceived benefits of an intervention.
Blinding, also known as masking, is a critical methodological procedure designed to mitigate this bias. It involves concealing information about treatment allocation from one or more individuals involved in the trial [24]. While blinding patients and treating clinicians is important, this article focuses specifically on the role of blinding outcome assessors—the personnel who collect, interpret, and adjudicate endpoint data. When these individuals are unaware of whether a patient received the experimental treatment or control, their assessments are less likely to be influenced by preconceptions about the treatment's effectiveness, thereby yielding more objective and reliable results [24] [23]. Empirical evidence demonstrates that non-blinded outcome assessors can exaggerate effect sizes, with one meta-analysis finding exaggerated odds ratios by an average of 36% in studies with binary outcomes [23].
Experimental Evidence: Quantitative Data on Blinding Effectiveness
The quantitative impact of unblinded outcome assessment is not merely theoretical. Data from real clinical trials and meta-analyses provide compelling evidence of the bias it introduces.
A salient example comes from the Interventional Management of Stroke (IMS) III trial, a prospective randomized open blinded endpoint (PROBE) design study [25]. In this trial, local outcome assessors, who were intended to be blinded, guessed the patient's actual treatment allocation significantly more often than would be expected by chance alone (58.2% correct guesses, p=0.0003). More importantly, the success of their guess was strongly associated with the patient's measured outcome. A correctly guessed allocation was associated with better scores on the modified Rankin Scale in the intervention group (cOR: 2.28, 95% CI: 1.50–3.48) and with worse scores in the control group (cOR: 0.47, 95% CI: 0.27–0.83). This interaction was highly significant (p<0.001), suggesting that the assessors' knowledge, or subconscious inference, of the treatment directly biased their assessment of this functional outcome [25].
Table 1: Association Between Correctly Guessed Treatment Allocation and 90-day Modified Rankin Scale Score in the IMS III Trial
| Actual Treatment Group | Assessor's Guess | Common Odds Ratio (cOR) for a Better mRS Score | 95% Confidence Interval |
|---|---|---|---|
| Intervention | Correct | 2.28 | 1.50 - 3.48 |
| Intervention | Incorrect | Reference | - |
| Control | Correct | 0.47 | 0.27 - 0.83 |
| Control | Incorrect | Reference | - |
These findings are consistent with broader meta-epidemiological studies. A series of meta-analyses by Hróbjartsson et al. quantified the impact of non-blinded assessment across different outcome types, demonstrating that failure to blind outcome assessors leads to a systematic overestimation of treatment effects [23].
Table 2: Summary of Meta-Analyses on the Impact of Non-Blinded Outcome Assessment on Effect Size
| Outcome Type | Exaggeration of Effect Size in Non-Blinded vs. Blinded Assessment | Source |
|---|---|---|
| Time-to-event outcomes | Exaggerated hazard ratios by 27% on average | Hróbjartsson et al. [23] |
| Binary outcomes | Exaggerated odds ratios by 36% on average | Hróbjartsson et al. [23] |
| Measurement scale outcomes | Exaggerated pooled effect size by 68% | Hróbjartsson et al. [23] |
Methodological Protocols for Blinding Outcome Assessors
Implementing effective blinding for outcome assessors requires deliberate planning and execution. The following protocols detail established methodologies.
Core Blinding Techniques
- Independent and Uninformed Assessors: The most fundamental technique is to employ outcome assessors who are not involved in the patient's clinical care and have no access to information that could reveal the treatment assignment. This includes shielding them from clinical notes, medication records, and conversations with the treating team [24].
- Centralized Adjudication Committees: For major, often subjective, clinical events (e.g., myocardial infarction, stroke), a common practice is to use a centralized committee of experts who adjudicate outcomes based on pre-specified, standardized criteria. This committee reviews source documents that have been redacted to remove any references to the treatment arm [23].
- Concealment of Physical Evidence: In surgical or device trials, physical evidence like incisions or scars can unintentionally unblind assessors. Techniques to prevent this include using identical dressings over all incision sites or conducting assessments via telephone to eliminate visual cues [24].
- Blinded Analysis of Diagnostic Data: For outcomes based on diagnostic tests (e.g., radiographs, pathology slides, lab results), the data can be anonymized and presented to assessors in a random order without identifying information. In some cases, advanced techniques like digitally altering radiographs to mask the type of implant used have been employed [24].
Validation and Quality Control
- Testing the Success of Blinding: It is considered good practice to formally test the success of blinding. At the end of the outcome assessment process, assessors can be asked to guess the treatment allocation for each participant. The results are then compared to what would be expected by chance (e.g., 50% for a two-arm trial), as demonstrated in the IMS III trial [25].
- Use of Negative Control Outcomes: A more advanced method to detect the presence of detection bias is the use of negative control outcomes [22]. These are outcomes that the treatment under study cannot plausibly affect (e.g., using a diagnosis of peptic ulcer as a negative control in a study of statins and diabetes). An association between the treatment and the negative control outcome suggests the presence of bias, including detection bias, provided the control outcome shares the same determinants of ascertainment as the primary outcome [22].
Comparative Analysis: Blinded Assessment vs. Traditional Proficiency Testing
The concept of ensuring accuracy in measurement has a direct parallel in laboratory medicine through Proficiency Testing (PT). A comparative analysis reveals both philosophical and practical distinctions between blinding in clinical trials and traditional PT, underscoring why blinding is the superior method for mitigating detection bias in therapeutic research.
Table 3: Comparison of Blinded Outcome Assessment and Laboratory Proficiency Testing
| Feature | Blinded Outcome Assessment in Clinical Trials | Traditional Laboratory Proficiency Testing |
|---|---|---|
| Primary Objective | Mitigate detection/ascertainment bias in outcome measurement [24] [22] | Ensure analytical accuracy and precision of lab test methods [14] |
| What is Tested | The objectivity and interpretation of the human assessor | The technical performance of equipment and reagents |
| Nature of Test | Integrated into actual patient follow-up; continuous process | External simulated samples; periodic event (e.g., 3x/year) [14] |
| State of Awareness | Assessor is unaware a "test" is occurring; mimics real conditions | Analyst is aware they are being tested, which may alter behavior [3] |
| Key Advantage | Prevents bias from influencing the primary study results | Identifies technical deficiencies in laboratory procedures |
A significant limitation of traditional PT is that it is predominantly declared or non-blinded, meaning the analysts know they are being evaluated. This awareness can trigger a "Hawthorne effect," where performance temporarily improves due to the knowledge of being observed, which may not reflect routine conditions [3]. In contrast, blind proficiency testing, where samples are submitted as routine patient samples, is recognized as a more robust method for testing the entire laboratory pipeline and is one of the only methods that can detect misconduct [3]. The implementation of blind PT in fields like forensic science faces logistical hurdles, but it represents a gold standard toward which testing programs can strive. This evolution mirrors the rationale in clinical trials: the most valid assessment occurs when the measurer is unaware that a measurement is being scrutinized, thereby ensuring the result reflects true performance rather than a reaction to being tested.
The Researcher's Toolkit: Essential Reagents and Materials
Successful implementation of blinding strategies often relies on specific materials and operational plans. Below is a list of key resources for designing a trial with blinded outcome assessment.
Table 4: Essential Reagents and Materials for Blinding Outcome Assessors
| Item / Solution | Function in Blinding |
|---|---|
| Redacted Source Documents | Physical or digital copies of medical records, imaging reports, and lab reports with all treatment identifiers removed. Serves as the primary data source for blinded adjudicators. |
| Centralized Adjudication Charter | A detailed, pre-approved protocol defining outcome definitions, procedures for review, and rules for handling ambiguous cases. Ensures standardized, objective judgment. |
| Telephone Interview Scripts | Standardized scripts for conducting patient interviews by phone, ensuring all patients are asked identical questions in the same way, minimizing verbal cues from the interviewer. |
| Digital Alteration Software | In surgical or device trials, software to anonymize or alter medical images (e.g., radiographs) to hide evidence of the specific intervention received. |
| Blinding Success Questionnaire | A short form administered to outcome assessors at the trial's end to record their guess of the treatment allocation and their confidence, used to validate blinding integrity [25]. |
Blinding outcome assessors is a foundational and non-negotiable methodology for mitigating detection bias in clinical trials. The experimental data is unequivocal: failure to implement and maintain this blinding leads to quantitatively exaggerated treatment effects, compromising the validity of trial results. While traditional proficiency testing provides a model for ensuring technical accuracy, the blinding of outcome assessors goes a step further by safeguarding the interpretative and subjective elements of clinical endpoint measurement. As clinical trials evolve to include more patient-centered and subjective outcomes, the rigorous application of these blinding protocols, validated by tests of blinding success and negative control outcomes, becomes ever more critical for generating evidence that truly informs clinical practice.
Proficiency Testing (PT) is an essential component of the quality management system in clinical and forensic laboratories, providing an external assessment of analytical performance [26]. Regular proficiency testing is widely accepted as a crucial element of a functioning quality assurance program, required at accredited laboratories to ensure accurate and reliable results [27] [3]. Two primary methodologies dominate this landscape: traditional (declared) proficiency testing and blind proficiency testing. In declared PT, laboratories receive samples clearly identified as performance tests, often following an announced schedule [28]. In contrast, blind proficiency testing involves samples disguised as routine patient specimens and submitted through normal analysis pipelines without examiners' knowledge [27] [28].
The fundamental distinction between these approaches lies in their implementation. Declared testing allows laboratories to anticipate and prepare for assessment, while blind testing aims to evaluate the entire testing process under normal operational conditions [27]. This comparative analysis examines the application, effectiveness, and methodological considerations of both paradigms across chemistry, immunology, and point-of-care testing domains, providing researchers and drug development professionals with evidence-based insights for quality assurance protocol selection.
Theoretical Foundations and Methodological Principles
Conceptual Frameworks
Blinding as a scientific principle aims to eliminate bias by withholding information that could influence behavior or interpretation [23]. In clinical trials, double-blind methodologies are considered the gold standard, where both participants and investigators remain unaware of treatment assignments to prevent conscious or unconscious influences on outcomes [29]. This same principle applies to laboratory proficiency testing, where knowledge of being evaluated can significantly alter testing behaviors and processes [27].
The theoretical foundation for blind proficiency testing rests on its ability to assess the entire laboratory pipeline under authentic conditions [27]. Unlike declared testing, which often targets specific analytical components, blind tests evaluate the complete process from specimen reception through analysis to reporting. This comprehensive assessment is particularly valuable for identifying systemic issues that might remain undetected in declared testing scenarios, including evidence handling, storage variables, and non-routine decision-making processes [8].
Error Categorization in Laboratory Testing
Understanding laboratory performance requires recognizing different error types. Conforming work represents proper method execution without deviations, while nonconforming work involves method deviations [27]. These deviations are categorized as:
- Mistakes: Innocent clerical errors detectable even by the original examiner
- Malpractice: Deviations from poor or incomplete training detectable through robust technical review
- Misconduct: Deliberate deviations difficult to detect as offending examiners may conceal them [27]
Blind proficiency testing uniquely addresses all error categories, including misconduct, which often evades other quality assurance methods [27].
Figure 1: Error Categorization in Laboratory Testing - Adapted from forensic science error classification [27]
Comparative Analysis: Blind vs. Traditional Proficiency Testing
Empirical Evidence from Direct Comparisons
A seminal comparative study on blood lead testing provides compelling quantitative evidence of performance differences between blind and traditional PT paradigms [28]. Researchers disguised aliquots from 72 blood lead performance pools as routine patient specimens and submitted them to 42 certified clinical laboratories, while the same laboratories received identical samples through traditional open PT programs.
Table 1: Blood Lead Proficiency Testing - Blind vs. Declared Paradigms [28]
| Performance Metric | Blind Testing | Traditional (Open) Testing | P-value |
|---|---|---|---|
| Unacceptable Results | 17.7% | 4.5% | <0.001 |
| Laboratories with Significant Performance Differences | 60% (13/22) | - | <0.05 |
| Laboratories with Unsuccessful Aggregate Performance | 32% (7/22) | 0% (Maintained successful performance) | - |
The study revealed that 60% of laboratories exhibited statistically significant performance differences between blind and open testing conditions, with nearly one-third demonstrating unsuccessful aggregate performance under blind testing while maintaining successful performance in traditional testing [28]. These findings suggest special efforts are often applied to declared proficiency samples that are not consistently maintained during routine testing operations.
Methodological Characteristics and Capabilities
Beyond quantitative performance measures, the two paradigms differ substantially in their implementation characteristics and quality assessment capabilities.
Table 2: Methodological Comparison of Proficiency Testing Approaches
| Characteristic | Blind Proficiency Testing | Traditional (Declared) Proficiency Testing |
|---|---|---|
| Sample Identity | Concealed; treated as routine specimens | Known; explicitly identified as PT samples |
| Testing Conditions | Normal operational workflow | Often special handling or prioritized processing |
| Error Detection Scope | Entire testing pipeline (pre-analytical to post-analytical) | Primarily analytical phase |
| Behavioral Influence | Avoids changes in examiner behavior | Examiners may dedicate extra time/attention |
| Misconduct Detection | Capable of identifying deliberate deviations | Limited capability |
| Ecological Validity | High; reflects real-world performance | Limited; may not represent routine conditions |
| Implementation Complexity | High; requires covert submission | Low; standard administrative process |
| Federal Laboratory Adoption | ~39% (primarily federal facilities) | Widespread (~98% of forensic labs) [27] |
| Cost & Resource Requirements | Generally higher | Generally lower |
Blind testing's primary advantage lies in its ability to assess the complete testing ecosystem, including pre-analytical phases such as specimen handling, storage, and processing that may introduce errors before analysis begins [27]. This comprehensive evaluation provides more authentic quality assessment than declared testing, which often focuses narrowly on analytical performance.
Implementation Across Laboratory Disciplines
Chemistry and Toxicology Applications
In chemical and toxicological analyses, blind proficiency testing has demonstrated particular value for identifying pre-analytical and analytical vulnerabilities. The Houston Forensic Science Center (HFSC) has implemented a robust blind testing program in toxicology that introduces mock evidence samples into ordinary workflows [8]. This approach has revealed process improvements needed throughout the testing pipeline that might remain undetected in declared testing scenarios.
The blood lead study exemplifies how chemical testing performance differs substantially between blind and declared conditions [28]. For lead testing, Clinical Laboratory Improvement Amendments (CLIA '88) establish acceptability criteria as ±0.19 μmol/L (±4 μg/dL) or ±10%, whichever is greater. The significantly higher unacceptable result rate in blind testing (17.7% versus 4.5%) suggests that without special treatment, many laboratories operate near or beyond acceptable performance boundaries for this critical chemical analyte.
Immunology and Serology Testing
Immunoassay-based testing, including serological analyses, presents unique challenges for proficiency testing due to the complex interaction between antibodies and target antigens [30]. Point-of-care immunology tests, such as lateral flow assays and vertical flow assays, increasingly incorporate machine learning to enhance interpretation [31]. These technological advances create new dimensions for proficiency assessment, particularly regarding the validation of automated interpretation systems.
While immunology-specific comparisons between blind and declared testing are less documented in the available literature, general principles from other disciplines apply. The potential for subjective interpretation in serological testing underscores the importance of blinding to prevent expectation bias, particularly for tests with qualitative or semi-quantitative results [27].
Point-of-Care Testing (POCT) Considerations
Point-of-care testing represents a rapidly expanding domain with distinct proficiency assessment challenges. POCT encompasses everything from basic dipsticks and handheld glucose meters to complex molecular analyzers [30] [32]. The ASSURED criteria (Affordable, Sensitive, Specific, User-friendly, Rapid and Robust, Equipment-free, and Deliverable) guide optimal POCT development and implementation [30].
Table 3: Point-of-Care Testing Characteristics and Quality Assessment [30] [32]
| POCT Feature | Proficiency Testing Considerations | Blind Testing Applicability |
|---|---|---|
| Rapid turnaround | Testing must account for time-sensitive decision making | Can evaluate real-time clinical decision impact |
| Decentralized testing | Quality assessment across multiple locations and operators | Challenges with standardized implementation across sites |
| Variety of operators | Differing expertise levels among users | Can assess performance across user variability |
| Direct clinical impact | Immediate treatment decisions based on results | Evaluates authentic clinical workflow integration |
| Technological diversity | Multiple platforms and methodologies | Requires customized approaches for different technologies |
POCT devices are particularly susceptible to interfering substances and have a narrow margin of error due to smaller sample sizes compared to conventional laboratory tests [30]. These characteristics make authentic assessment through blind testing particularly valuable, though implementation challenges exist due to testing decentralization and operator variability.
Experimental Protocols and Methodologies
Blind Proficiency Testing Implementation Framework
Implementing effective blind proficiency testing requires systematic planning and execution. The Houston Forensic Science Center's program across six disciplines provides a model framework [8]. Their methodology includes:
Sample Preparation: Mock evidence samples are created to closely resemble routine specimens in appearance, composition, and packaging. For toxicology testing, this includes preparing samples with controlled substances at concentrations spanning the analytical measurement range.
Covert Submission: Samples enter the testing pipeline through normal submission channels without special identification. Case managers serve as buffers between requestors and analysts, facilitating blind introduction without compromising workflow.
Documentation and Tracking: Each blind sample is tracked through the complete testing process using standard laboratory information systems, with additional monitoring to ensure proper evaluation upon completion.
Result Evaluation: After analysis and reporting, blind test results are compared to known target values using established acceptability criteria (e.g., CLIA standards for clinical tests).
Root Cause Analysis: Unacceptable results trigger comprehensive investigation to identify process failures, which may include specimen handling, analytical errors, calibration issues, or reporting inaccuracies.
Blood Lead Testing Comparative Protocol
The blood lead proficiency comparison study employed a rigorous methodology that serves as a template for similar comparative assessments [28]:
Phase 1: Blind Sample Distribution
- Aliquots from performance pools were disguised as routine patient specimens
- Samples submitted to participating laboratories through normal channels
- Laboratories unaware of participation in special study
Phase 2: Traditional Proficiency Testing
- Same laboratories received aliquots of identical performance samples through declared PT programs
- Samples clearly identified as proficiency testing materials
- Standard PT scheduling and reporting procedures followed
Analysis:
- All results scored against CLIA '88 acceptability criteria (±0.19 μmol/L or ±10%)
- Statistical comparison of performance between blind and declared paradigms
- Aggregate performance assessment using standard PT scoring (80% minimum for successful performance)
This direct comparison within the same laboratories using identical target samples provides high-quality evidence of paradigm-dependent performance differences.
Figure 2: Comparative Testing Protocol Workflow - Based on blood lead study methodology [28]
The Scientist's Toolkit: Research Reagent Solutions
Implementing proficiency testing programs requires specific materials and methodologies to ensure valid, reproducible results. The following essential components form the foundation of robust testing protocols.
Table 4: Essential Research Reagents and Materials for Proficiency Testing
| Item | Function | Application Notes |
|---|---|---|
| Performance Testing Samples | Target materials with known concentrations/characteristics | Must mimic real patient specimens; stability verification critical |
| Matrix-Appropriate Materials | Provide biological context for analyses (serum, whole blood, urine) | Matrix effects significantly impact analytical performance |
| Blind Testing Containers | Identical to routine specimen collection containers | Maintains deception essential for authentic blind assessment |
| Stability Preservation Reagents | Maintain analyte integrity during storage and shipping | Particularly crucial for labile analytes in chemistry and immunology |
| Interference Testing Materials | Assess assay specificity against common interferents (hemoglobin, lipids) | Identifies susceptibility to false positives/negatives |
| Calibration Verification Materials | Independent materials for accuracy assessment | Should be different from calibration materials used routinely |
| Data Management System | Tracks blind samples through entire testing process | Maintains blinding while ensuring result capture and evaluation |
These materials enable laboratories to implement both traditional and blind proficiency testing protocols that generate meaningful performance data. For blind testing specifically, the authenticity of materials and their introduction into normal workflows is paramount for valid assessment [27] [28].
The comparative analysis of blind versus traditional proficiency testing reveals significant differences in their ability to assess true laboratory performance. Empirical evidence demonstrates that declared testing consistently produces better performance metrics than blind assessment, suggesting special efforts are often applied to known proficiency samples [28]. This performance gap has important implications for quality assurance programs and patient safety initiatives across chemistry, immunology, and point-of-care testing domains.
Blind proficiency testing offers superior ecological validity by evaluating the complete testing pipeline under normal operational conditions, providing unique capability to detect pre-analytical errors and systematic issues that declared testing may miss [27]. However, implementation challenges including resource requirements and logistical complexity have limited its widespread adoption, particularly outside federal forensic facilities [27]. Traditional proficiency testing remains valuable for assessing analytical performance under optimal conditions and meets current accreditation requirements, but may overestimate routine testing quality.
For researchers and drug development professionals, these findings underscore the importance of methodological considerations when designing quality assessment protocols and interpreting proficiency testing results. The optimal approach may involve a balanced strategy incorporating both declared testing for ongoing analytical monitoring and periodic blind assessment for comprehensive system evaluation. As laboratory medicine continues to evolve with advancing technologies including machine learning and enhanced point-of-care platforms [31], robust proficiency testing methodologies will remain essential for ensuring diagnostic accuracy and patient safety.
Navigating Implementation Hurdles and Strategic Optimization
Blind testing, a paradigm where those being tested are unaware they are being evaluated, is recognized for its potential to yield more authentic performance data by reducing biases and "special effort" behaviors inherent in traditional, declared (open) proficiency testing [28] [3]. Despite its advantages, widespread adoption faces significant hurdles. This guide provides a comparative analysis of blind versus open testing, detailing the obstacles and offering a framework for implementation, drawing on evidence from clinical, forensic, and industrial research.
Blind vs. Open Testing: A Performance Data Comparison
A foundational study in clinical chemistry directly compared open and blind proficiency testing for blood lead analysis, revealing a stark performance disparity. The data demonstrates that blind testing is a more rigorous and less forgiving measure of real-world laboratory proficiency.
The table below summarizes the key quantitative findings from this comparative study.
Table 1: Comparative Performance in Blood Lead Open vs. Blind Proficiency Testing [28]
| Testing Paradigm | Number of Laboratories | Total PT Results | Unacceptable Results | Statistical Significance |
|---|---|---|---|---|
| Open Testing | 42 | Not Specified | 4.5% | P < 0.001 |
| Blind Testing | 42 | Not Specified | 17.7% |
The study further found that 60% of laboratories showed a statistically significant difference (P < 0.05) between their blind and open test performances [28]. Importantly, seven laboratories (32%) maintained successful aggregate performance in open testing while having unsuccessful performance in blind testing, with two cases showing gross discrepancies [28]. This confirms that the act of knowing a sample is a test can significantly alter laboratory behavior and results.
Deconstructing the Barriers to Blind Testing
Implementing blind testing is fraught with challenges across logistical, cultural, and resource dimensions. These barriers explain why open testing remains the dominant model despite its known limitations.
Table 2: Multifaceted Barriers to Implementing Blind Testing
| Barrier Category | Specific Challenges | Field of Evidence |
|---|---|---|
| Logistical & Operational | Designing tests that perfectly mimic real-case samples; Submitting disguised samples without disrupting workflow; High resource overhead for coordination [3]. | Forensic Science [3] |
| Cultural & Behavioral | Resistance from professionals fearing loss of control; Reluctance to trust a system that removes "gut instinct"; Uncomfortable with potential outcomes that may reveal performance issues [3] [33]. | Forensic Science, Hiring |
| Resource & Economic | Significant upfront investment in design and execution; Ongoing costs of sample creation and submission; Requires specialized staff or consultants to manage [3]. | Forensic Science |
A critical cultural obstacle is the fear of outcomes. Organizations may resist blind testing because they fear the results could reveal flaws that open testing masks, potentially leading to legal, financial, or reputational damage [33]. Furthermore, there is a philosophical argument that anonymization can force individuals to "erase their identity," which, while intended to prevent bias, can be seen as a form of damage control rather than true equity [33].
Experimental Protocols for Blind Testing
The validity of blind testing depends on rigorous methodologies that ensure the test is indistinguishable from routine work. The following protocols are adapted from successful implementations in clinical and forensic settings.
Protocol 1: Disguised Sample Submission for Laboratory Proficiency
This methodology is designed to evaluate the routine performance of clinical or analytical laboratories without their knowledge.
- Objective: To compare laboratory performance on blinded proficiency samples versus open proficiency samples for a given analyte (e.g., blood lead) [28].
- Sample Preparation: Aliquots from well-characterized performance pools are obtained from a proficiency testing (PT) provider. These pools have predefined target values and acceptable ranges based on established criteria (e.g., CLIA '88) [28].
- Blinding Procedure: The aliquots are disguised as routine patient specimens. This involves using the same sample containers, labeling, and requisition forms as used for standard patient samples submitted to the laboratory [28].
- Submission and Analysis: The disguised samples are submitted to participating laboratories through their standard sample intake process alongside genuine patient specimens. Laboratories analyze the samples using their routine methods and protocols [28].
- Open Testing Control: The same laboratories receive aliquots from the same performance pools directly from the PT provider as declared, open PT samples [28].
- Data Analysis and Scoring: Results from both the blind and open samples are scored against the same acceptable target range (e.g.,
± 0.19 µmol/L or ± 10%). The rates of unacceptable results and individual laboratory performances are statistically compared between the two paradigms [28].
Protocol 2: Blind Proficiency Testing in Forensic Laboratories
This protocol tests the entire forensic analysis pipeline, from evidence intake to final reporting, under realistic conditions.
- Objective: To assess the accuracy and reliability of forensic laboratory analyses and conclusions without the examiners knowing they are being tested [3].
- Test Design: A blind proficiency test must be crafted to resemble an actual case in every detail. The test material should not have any features that would alert an examiner to its true nature as a test [3].
- Integration into Workflow: The test case is inserted into the laboratory's normal workflow through the standard evidence intake system. It must be processed alongside genuine casework, following all standard operating procedures [3].
- Evaluation: The final report from the blind test is evaluated against the known ground truth of the test sample. The analysis checks for factual accuracy, adherence to methodological standards, and the correctness of any conclusive statements [3].
- Key Consideration: The logistical challenge of creating realistic case simulations and integrating them without detection is the primary hurdle. This often requires coordination with external entities, such as law enforcement agencies, to facilitate the submission [3].
Visualizing Testing Workflows and Barriers
The following diagrams illustrate the core workflows of both testing paradigms and synthesize the key obstacles into a logical framework.
Blind vs. Open Testing Workflow
This diagram contrasts the procedural pathways of blind and open proficiency testing, highlighting the critical divergence point of tester awareness.
Obstacle Pathway to Blind Testing
This diagram maps the primary logistical, cultural, and resource barriers that hinder the implementation of blind testing programs.
The Researcher's Toolkit for Blind Testing
Successful design and execution of a blind testing program require specific components and strategic approaches.
Table 3: Essential Components for a Blind Testing Framework
| Component / Solution | Category | Function & Importance |
|---|---|---|
| Structured Scorecards | Methodology | Provides objective, consistent evaluation criteria for all results, replacing subjective "gut feeling" and reducing bias in the assessment phase [33]. |
| Scenario Modeling Tools | Technology | Digital twins or other simulation tools can model "what if" scenarios to refine test design and predict workflow impacts before live implementation [34]. |
| Predictive Analytics | Technology | AI and machine learning can help analyze historical data to forecast potential disruptions and optimize test integration points [34]. |
| Collaborative Partnerships | Strategy | Engaging with external organizations (e.g., other labs, agencies) is often crucial for creating realistic test scenarios and managing disguised submissions [3]. |
| Clear Communication Plan | Strategy | Managing cultural resistance requires transparent communication about the goals of blind testing (improvement, not punishment) to secure buy-in from staff and leadership [33]. |
The empirical evidence is clear: blind testing provides a more accurate assessment of true operational proficiency by eliminating the performance bias inherent in open testing [28]. However, the path to implementation is complex, requiring careful navigation of significant logistical, cultural, and financial obstacles [3] [33]. Overcoming these barriers is not merely a technical challenge but a strategic one. It demands investment in robust methodologies, technologies for integration and analysis, and, most importantly, a cultural shift within organizations toward valuing authentic performance data over the comfort of controlled assessments. For researchers and professionals committed to the highest standards of quality and accuracy, mastering the obstacles to blind testing is not an option, but a necessity.
The April 2025 suspension of the U.S. Food and Drug Administration's (FDA) Grade "A" Milk Proficiency Testing (PT) Program offers a critical case study in the vulnerabilities of traditional, open proficiency testing systems [9]. This event, triggered by federal workforce reductions and the closure of the FDA's Moffett Center Proficiency Testing Laboratory, disrupted a long-established quality assurance mechanism within the U.S. dairy industry [9] [35]. For researchers and scientists in drug development and quality systems, this incident provides a real-world framework for analyzing fundamental questions about quality assurance design: How do different proficiency testing paradigms perform under scrutiny? What vulnerabilities emerge when established systems are disrupted?
This analysis examines the FDA Milk PT suspension through the theoretical lens of blind versus traditional proficiency testing. It moves beyond the immediate regulatory context to explore comparative data on testing methodologies, their resistance to performance bias, and their ecological validity in simulating real-world conditions. The suspension creates a natural experiment, revealing the strengths and weaknesses of a centralized, open PT system and offering insights for designing more resilient quality assurance protocols across scientific fields.
The FDA Milk Proficiency Testing Program: Structure and Suspension
Historical and Operational Framework
The FDA's Milk Proficiency Testing Program was a mature component of the U.S. dairy safety system, rooted in the Grade "A" Pasteurized Milk Ordinance (PMO) [9]. Its core function was to ensure analytical uniformity and accuracy across the network of laboratories testing Grade "A" milk for safety and quality [9]. The program operated as a federal-state partnership, with a well-defined annual cycle:
- Sample Preparation and Distribution: The Wisconsin Department of Agriculture, Trade and Consumer Protection (DATCP) Bureau of Laboratory Services prepared and shipped standardized samples of milk or dairy products spiked with known levels of contaminants to participating laboratories nationwide [9].
- Analysis and Reporting: Participating laboratories analyzed these samples for key safety parameters, including Standard Plate Count, Coliform count, drug residues, and Somatic Cell Count, submitting their results for evaluation [9].
- Data Analysis and Evaluation: The FDA's Moffett Center Proficiency Testing Laboratory was responsible for collating results and statistically analyzing them against established targets to determine acceptable performance [9].
This system verified that hundreds of certified analysts could accurately detect bacteria, drug residues, and other contaminants at required levels, forming a critical checkpoint in the broader milk safety system [9].
Circumstances of the Suspension and Immediate Aftermath
In April 2025, the FDA suspended this program indefinitely. The primary reason cited was a severe reduction in the FDA's food safety workforce, which rendered the Moffett Center laboratory unable to provide the necessary support for proficiency testing and data analysis [9] [35]. This was part of broader federal workforce cuts affecting the Department of Health and Human Services [35] [36].
The industry response, led by organizations like the International Dairy Foods Association (IDFA) and the National Milk Producers Federation (NMPF), was swift and aimed at public reassurance. They emphasized that the suspension affected a laboratory evaluation tool, not the routine safety tests performed on milk itself [37] [38]. The FDA and industry groups clarified that all mandatory testing on farms, during transport, and at processing plants continued unchanged under the Pasteurized Milk Ordinance [38] [39]. The FDA stated it was "actively evaluating alternative approaches" for the proficiency evaluation of laboratories [35].
Comparative Analysis: Blind Versus Traditional Proficiency Testing Paradigms
The FDA Milk PT Program exemplified a traditional, open proficiency testing model. A comparative analysis with blind proficiency testing reveals significant differences in design, implementation, and potential for performance bias, which are critical for understanding system vulnerabilities.
The table below summarizes the core structural differences between these two paradigms:
Table 1: Comparison of Traditional (Open) and Blind Proficiency Testing Paradigms
| Feature | Traditional (Open) PT | Blind PT |
|---|---|---|
| Sample Identity | Known to laboratory as PT sample [28] | Disguised as routine patient/sample [3] [40] |
| Testing Schedule | Announced in advance [28] | Unannounced, random [3] |
| Ecological Validity | Lower; may not reflect routine workflow [40] | Higher; tests the entire laboratory pipeline under normal conditions [3] |
| Primary Purpose | Direct assessment of analytical competency | Assessment of total testing process, including pre-analytical phases |
| Ability to Detect Misconduct | Limited | One of the only methods to detect misconduct [3] |
| Logistical Complexity | Lower; easier to administer nationally [40] | Higher; presents logistical and cultural obstacles [3] |
| Example Context | FDA Milk PT, CDC PT programs [9] [40] | Federal forensic facilities, some medical/drug testing [3] |
Empirical Evidence of Performance Disparities
Research across multiple scientific fields consistently demonstrates that laboratory performance can differ significantly between open and blind testing protocols.
- Clinical Drug Testing: A seminal 1977 study compared laboratory performance using identical samples distributed both blindly and by mail. Most laboratories performed acceptably with the mail-distributed samples, but many performed poorly when the identical samples were submitted as simulated patient specimens [40]. This highlighted the limitations of mail-distribution models and the impracticality of extensive national blind testing at that time [40].
- Blood Lead Analysis: A 2001 study directly compared open and blind testing for blood lead levels. It found that 17.7% of all blind PT results were classified as unacceptable, compared to only 4.5% of open PT results [28]. Approximately 60% of the clinical laboratories exhibited a statistically significant difference in their performance between the two paradigms, generally performing better on open PT samples [28]. The study concluded that occasional use of blind PT could deter the inclination to treat performance samples with special care [28].
These findings point to a "PT enhancement effect" in open systems, where laboratories may apply extraordinary effort to known test samples, thereby creating a potential gap between measured proficiency and routine performance.
Methodological Workflows: Traditional vs. Blind PT
The following diagram illustrates the key procedural differences between the traditional (open) PT model, as used by the FDA milk program, and the blind PT model.
Vulnerability Analysis of the Suspended FDA Milk PT Program
The suspension of the FDA Milk PT program exposes several structural vulnerabilities inherent in its design as a centralized, open PT system.
- Centralized Data Analysis as a Single Point of Failure: The program relied on a single federal facility, the Moffett Center Laboratory, for the critical final step of data analysis and evaluation [9]. This created a critical vulnerability, as the incapacitation of this single node was sufficient to halt the entire national program. A more decentralized analysis structure, potentially distributed among state or regional partners, could have offered greater resilience.
- Dependence on Open Testing Design: As an open PT system, the program was potentially susceptible to the performance bias documented in other fields [28]. While the program showed a historical trend of improving lab performance over time, this improvement may reflect growing familiarity with the open testing format as much as genuine enhancement of routine testing accuracy [9].
- Logistical Challenges in Transitioning to Blind Testing: Implementing a blind PT system for a geographically dispersed and product-diverse industry like dairy presents immense logistical hurdles [3]. Creating blind samples that are indistinguishable from routine farm or processor samples and integrating them into normal supply chains would be complex and costly, explaining the historical reliance on the more straightforward open model [40].
The Scientist's Toolkit: Research Reagents and Methods for Proficiency Testing
Research into proficiency testing methodologies relies on a specific set of reagents, materials, and analytical techniques. The following table details key components relevant to the field, drawing from the protocols of the FDA milk program and general PT research.
Table 2: Key Research Reagents and Materials for Proficiency Testing
| Item/Solution | Function in Proficiency Testing | Example from Milk PT Context |
|---|---|---|
| Spiked/Manufactured PT Samples | Core test material with known analyte concentrations; used to challenge laboratory accuracy. | Milk samples spiked with known levels of bacteria (e.g., for SPC), drug residues (e.g., beta-lactams), or somatic cells [9] [37]. |
| Culture Media & Agar | Supports the growth of microorganisms for microbiological enumeration and identification. | Used for Standard Plate Count (SPC), Coliform count, and Plate Loop Count (PLC) [9]. |
| Rapid Test Kits & Reagents | Provides rapid, specific detection of target analytes like drug residues. | IDEXX or Charm test kits for antibiotic residue screening, as mandated in Appendix N of the PMO [9]. |
| Reference Materials | Provides a gold-standard value for comparison; essential for statistical analysis of PT results. | Analyzed by FDA reference labs to establish "true" values for spiked samples before distribution [37]. |
| Statistical Analysis Software | Evaluates participant lab results against target values using standardized scoring algorithms (e.g., z-scores). | Used by the FDA's Moffett Center to collate and analyze results from all participating laboratories [9]. |
The 2025 suspension of the FDA's Milk Proficiency Testing Program serves as a potent case study in the vulnerabilities of centralized, open proficiency testing systems. The analysis reveals that while such programs are logistically efficient and can drive continuous improvement, they possess critical single points of failure and may be susceptible to performance biases that overstate real-world analytical consistency.
The comparative framework of blind versus traditional PT highlights a fundamental trade-off: open PT offers scalability and practicality, while blind PT provides superior ecological validity and resistance to bias. For researchers and quality assurance professionals designing testing protocols, the lesson is clear. Building resilient quality systems requires a multifaceted approach. Relying on a single, centralized PT model creates systemic risk. The most robust strategy may involve a hybrid approach, combining regular open PT for training and continuous competency assessment with periodic, randomized blind PT to validate the entire testing pipeline and ensure that measured proficiency translates into consistent daily performance. Future research should focus on developing more feasible and cost-effective methods for implementing blind testing in large-scale, decentralized industries to mitigate the vulnerabilities exposed by this case.
In the competitive and highly regulated field of drug development, robust comparative analysis is fundamental for establishing the efficacy, safety, and quality of new therapeutic products. Researchers, scientists, and drug development professionals routinely employ various testing paradigms to generate reliable data for regulatory submissions and internal decision-making. Within this context, two primary approaches for evaluating analytical performance exist: traditional (open) proficiency testing and blind proficiency testing. Traditional proficiency testing involves distributing clearly identified performance samples to laboratories on an announced schedule, allowing them to prepare for the assessment. In contrast, blind proficiency testing involves submitting known samples disguised as routine patient specimens or casework, providing a more authentic measure of daily operational performance [17] [28]. The strategic choice between these methodologies carries significant implications for data integrity, stakeholder confidence, and ultimately, the success of a drug development program. This guide provides an objective comparison of these approaches, supported by experimental data and detailed protocols, to help research teams overcome practical constraints and secure crucial stakeholder buy-in for their chosen testing strategy.
Comparative Analysis: Blind Testing vs. Traditional Proficiency Testing
A direct comparison of performance outcomes between blind and traditional proficiency testing reveals significant disparities. The table below summarizes quantitative findings from a controlled study evaluating clinical laboratory performance for blood lead analysis under both paradigms.
Table 1: Comparative Performance in Blood Lead Analysis: Blind vs. Open Proficiency Testing [28]
| Performance Metric | Blind Proficiency Testing | Traditional (Open) Proficiency Testing |
|---|---|---|
| Overall Unacceptable Results | 17.7% | 4.5% |
| Laboratories with Statistically Significant Performance Difference | 60% (13 of 22 labs) | - |
| Laboratories with Unsuccessful Aggregate Performance | 32% (7 of 22 labs) | 0% (Same 7 labs maintained successful performance) |
| Primary Advantage | Measures routine performance; detects misconduct; tests entire laboratory pipeline. | Helps laboratories identify and correct methodological issues in a controlled setting. |
| Main Disadvantage | Logistically challenging to implement; can be resource-intensive. | May not reflect routine performance; examiners know they are being tested. |
The data indicates that a substantial proportion of laboratories perform differently when analyzing known proficiency samples versus routine specimens. While most laboratories performed acceptably with traditional open samples, many performed poorly when the identical samples were submitted as blind specimens [28]. This performance gap suggests that some laboratories may make special efforts when handling samples identified as part of a proficiency test, a behavior that blind testing is designed to deter [28]. The differences, however, are not always clinically significant, and traditional testing remains a valuable tool for methodological refinement [28].
Experimental Protocols and Methodologies
Protocol for Implementing Blind Proficiency Testing
The successful execution of a blind proficiency study requires meticulous planning to ensure the samples are processed as routine casework. The following workflow details the key steps:
Title: Blind Proficiency Testing Workflow
Detailed Methodology:
- Sample Preparation: Create well-characterized performance testing samples with known target values. These can be identical to those used in a traditional open proficiency testing program [28].
- Collaboration with a Third Party: Engage a collaborating partner, such as a hospital administrator or a trusted external entity. This partner will act as the submitter to maintain the blind nature of the test [17] [28].
- Blind Submission: The collaborator forwards the samples to the supporting laboratory "as though they were ordinary specimens from patients" [28]. This step is critical for ecological validity.
- Laboratory Analysis: The laboratory processes and analyzes the samples according to its standard operating procedures for routine casework, with no knowledge that they are part of a proficiency test [17].
- Data Collection and Scoring: Collect all results and score them against pre-defined acceptable target ranges using relevant criteria (e.g., CLIA '88 criteria for clinical labs) [28].
- Analysis and Feedback: Analyze the data to assess performance, identify any systematic issues, and provide constructive feedback to the laboratory. This process provides insights into "workflow, customer service, and scientific accuracy" [17].
Protocol for Traditional (Open) Proficiency Testing
Traditional proficiency testing follows a more direct and declared approach, as outlined below.
Title: Traditional Proficiency Testing Workflow
Detailed Methodology:
- Program Enrollment and Schedule Announcement: Laboratories enroll in a proficiency testing (PT) program and receive a shipping schedule announced in advance [28].
- Direct Distribution of Identified PT Samples: The program provider ships clearly identified performance samples directly to the participating laboratory [28].
- Laboratory Analysis: The laboratory analyzes the samples with the knowledge that they are part of a formal proficiency assessment. This awareness may lead to the samples being handled by senior personnel or with increased diligence [17] [28].
- Result Submission and Performance Report: The laboratory submits its results to the PT provider, which then generates a performance report comparing the laboratory's results to the target values and the performance of peers.
- Corrective Actions: If unacceptable results are obtained, the laboratory must initiate and document corrective actions to address the root cause of the performance issue.
The Scientist's Toolkit: Key Research Reagent Solutions
The following table details essential materials and their functions in conducting robust comparative analyses in drug development.
Table 2: Essential Research Reagents for Comparative Analysis and Proficiency Testing
| Reagent/Material | Function in Comparative Analysis |
|---|---|
| Certified Reference Materials | Provides a definitive standard with known property values, used to calibrate apparatus and validate methods. Essential for preparing accurate proficiency testing samples. |
| Performance Testing Samples | Simulated patient specimens or drug products with predetermined target values, used to evaluate a laboratory's analytical performance in both blind and open paradigms [28]. |
| Chemogenomic Data | Integrates chemical structure and genomic information to predict drug-target interactions (DTIs), enabling computational comparison of drug efficacies [41]. |
| Common Comparators | A standard drug or treatment (e.g., a placebo or active control) used as a link in adjusted indirect comparisons to estimate the relative efficacy between two interventions that have not been directly compared in head-to-head trials [42]. |
| Statistical Software for Indirect Comparison | Facilitates complex statistical analyses, such as adjusted indirect comparisons or mixed treatment comparisons, which are accepted by health technology assessment bodies for comparative drug evaluation [42]. |
Overcoming Practical Constraints and Ensuring Stakeholder Buy-in
Implementing a robust testing strategy, particularly one involving blind protocols, requires proactively addressing practical challenges and communicating value effectively to stakeholders.
Addressing Logistical and Cultural Obstacles: The implementation of blind testing in scientific laboratories faces both logistical and cultural hurdles [16]. Logistically, creating a seamless process for submitting blind samples that mimic real casework requires coordination with third-party partners. Culturally, there may be apprehension that the results could be used punitively. To overcome this, frame blind testing as a systems-level quality improvement tool rather than an individual performance evaluation. Leadership should emphasize its role in providing the most realistic data on laboratory performance, which ultimately strengthens the validity of the evidence generated for regulatory submissions [17].
Securing Regulatory and Practitioner Trust: For stakeholders in drug development, such as regulatory agencies and clinical researchers, the credibility, objectivity, and transparency of comparative research are paramount [43]. While adjusted indirect comparison methods are accepted by bodies like NICE and the CADTH, they inherently carry more uncertainty than direct head-to-head trials [42]. To build buy-in for any comparative methodology, whether for clinical outcomes or laboratory proficiency, the research must be conducted with open and transparent practices. Demonstrating that studies are objective and not politically motivated builds the necessary credibility for results to be trusted and utilized in decision-making [43].
Leveraging a Hybrid Approach for Continuous Improvement: A strategic, phased approach can be effective for gaining support. Instead of a full-scale immediate rollout, laboratories can begin with pilot blind testing programs on a limited scale. This allows for the refinement of logistics and the demonstration of value with manageable resource investment. Furthermore, positioning blind testing as a complement to, rather than a replacement for, traditional proficiency testing can alleviate concerns [17] [16]. Traditional testing is excellent for method validation and identifying gross deficiencies, while blind testing provides an ongoing, realistic monitor of daily performance. Presenting them as complementary components of a comprehensive quality system is a persuasive strategy for securing stakeholder buy-in.
Leveraging Technology and Standardization for Efficient PT Management
Proficiency Testing (PT) is a fundamental tool for ensuring the quality and accuracy of laboratory test results by comparing them to established standards or the results of other laboratories. It serves as an external validation mechanism to monitor a laboratory's ongoing capability to produce reliable data, which is especially critical in drug development where errors can have significant implications for patient safety and regulatory approval [44]. Within the context of comparative analysis, PT is often contrasted with other quality assessment methods, such as traditional "blind testing" approaches, to evaluate their respective efficiencies and reliabilities in various research and development settings.
The core objective of any PT scheme is to assess the technical competence of a laboratory. Unlike method-validation exercises like Ring Trials, which use standardized protocols to harmonize techniques across laboratories, PT requires each participating laboratory to use its own routine methods and equipment. This provides a realistic assessment of a laboratory's day-to-day performance and the reliability of its results in a real-world context [45]. For researchers and scientists in drug development, consistent and satisfactory performance in PT is not merely an operational goal but a strategic imperative that underpins the integrity of clinical trial data and subsequent regulatory submissions.
Comparative Analysis: Blind Testing vs. Traditional Proficiency Testing
A clear understanding of the distinctions between different interlaboratory assessment methods is crucial for effective quality management. The following table outlines the key differences between Ring Trials (a form of method-focused blind testing) and traditional Proficiency Testing (a laboratory-focused assessment) [45].
Table: Key Differences Between Ring Trials and Proficiency Testing
| Feature | Ring Trials (Interlaboratory Tests) | Proficiency Testing (PT) |
|---|---|---|
| Main Objective | Evaluation and validation of analytical methods. | Assessment of a laboratory's technical competence. |
| Reference Values | May be derived from participants' results. | Pre-established and concealed from participants, or derived from participant consensus. |
| Frequency | Occasional, as needed for method validation. | Regular and periodic, as part of ongoing quality control. |
| Operating Conditions | Standardized protocols to minimize methodological variations. | Each laboratory uses its own method, equipment, and reagents. |
| Participation | Voluntary, for method harmonization and development. | Often mandatory for laboratory accreditation under international regulations. |
| Primary Application | Development, validation, and harmonization of analytical methods. | Quality control and compliance with accreditation standards. |
Ring Trials are designed to assess the reproducibility of an analytical method itself. In a Ring Trial, multiple laboratories analyze the same sample using an identical, pre-defined protocol. The goal is to identify and reduce variability between laboratories, thereby harmonizing and validating the method. The focus is on the method's performance under controlled conditions [45].
In contrast, Proficiency Testing evaluates the competence of the laboratory personnel and the overall testing system. Laboratories use their standard operating procedures to analyze PT samples, which are treated as routine patient or quality control materials. The results reveal how accurately the laboratory can perform a specific test in its normal working environment, providing a direct measure of operational quality [45]. It is this focus on real-world laboratory performance that makes PT a cornerstone of accreditation standards like ISO/IEC 17025 [45].
The Workflow of a Proficiency Testing Scheme
The process of PT, from preparation to corrective action, involves multiple critical stages that ensure its effectiveness as a quality assurance tool. The following diagram illustrates the typical workflow for a laboratory participating in a PT scheme.
Technological Advancements in PT Management
The management of PT programs is being transformed by digital technologies, which enhance efficiency, traceability, and analytical depth. A significant development is the move towards digitization and centralized data platforms. For instance, recent initiatives in other highly regulated sectors have seen the launch of certification digital platforms and expert databases, which streamline the management of technical standards and certification processes [46]. In a PT context, similar platforms can facilitate the seamless distribution of samples, submission of results, and delivery of performance reports, reducing administrative burdens and potential for error.
Artificial Intelligence (AI) and automation are also making inroads. The broader field of drug discovery is increasingly leveraging AI-driven autonomous labs, where robotic platforms execute high-throughput experiments guided by AI algorithms that can predict outcomes and optimize processes [47]. This technological paradigm can be adapted to PT management. AI can be used to analyze vast datasets from PT results to identify subtle patterns of systematic errors or biases that might escape manual review. Furthermore, automation ensures that PT samples are processed with the same consistency as routine samples, mitigating the risk of "special handling" which can skew performance assessment [44].
The Role of AI and Automation in Modern PT
The integration of AI and robotics creates a powerful synergy for modernizing quality control workflows. The diagram below outlines how this integrated system functions in a contemporary laboratory setting.
Experimental Protocols and Data-Driven Performance Analysis
Adherence to robust experimental protocols is critical for generating meaningful PT data. The methodology begins with sample preparation and homogeneity testing. The PT provider must ensure that all samples distributed are identical and stable, as variations in the sample itself would invalidate any inter-laboratory comparison [45]. Following receipt, laboratories must process PT samples using identical standard operating procedures (SOPs) as those for routine patient samples. This includes using the same calibrators, quality control materials, instrumentation, and personnel [44]. A common pitfall is assigning PT samples to more experienced staff or using different methodologies, which does not provide a true reflection of routine laboratory performance.
Data analysis and performance scoring are typically conducted using statistical methods. A common approach is the use of z-scores, which quantify how far a laboratory's result is from the target value, as measured in units of standard deviation. A z-score between -2 and +2 is generally considered satisfactory, while a score beyond this range indicates unacceptable performance [44]. For some analytes, percentage-based limits or a combination of absolute and percentage limits are applied to account for concentration-dependent variability. For example, updated regulations set performance limits for bilirubin at ±20% or ±0.4 mg/dL, whichever is more tolerant [14].
Quantitative Analysis of PT Performance
Data from PT schemes provide invaluable insights into laboratory performance and common sources of error. A review of unacceptable PT results in medical laboratories highlights the distribution of errors across the testing process. The following table summarizes the factors contributing to poor performance based on an analysis of PT data [44].
Table: Analysis of Factors Contributing to Unacceptable PT Results
| Error Category | Specific Factors | Impact on Performance |
|---|---|---|
| Pre-analytical Errors | Incorrect sample reconstitution, improper storage, transcription errors. | Introduces bias before analysis begins, leading to systematic deviation from true value. |
| Analytical Errors | Instrument malfunction, calibration drift, reagent lot variation, failure of internal quality control. | Causes both random and systematic errors, affecting precision and accuracy. |
| Post-analytical Errors | Data entry mistakes, incorrect unit conversion, reporting against the wrong peer group. | Results in correct analytical data being reported incorrectly, leading to PT failure. |
| Methodological Issues | Treating PT samples differently from patient samples ("special handling"). | Creates an artificial performance environment that does not reflect routine competency. |
The consequences of these errors are significant. Studies indicate that laboratories with inconsistent performance or frequent unacceptable results may face scrutiny from regulatory bodies and risk losing their accreditation [44]. More importantly, these errors are indicative of potential lapses in patient sample testing, which can directly impact diagnostic accuracy and treatment efficacy in clinical trials and healthcare.
The Scientist's Toolkit: Essential Research Reagent Solutions
The reliability of any PT exercise is contingent on the quality of materials used throughout the process. The following table details key reagents and solutions essential for conducting robust PT and related analytical experiments.
Table: Key Reagent Solutions for Proficiency Testing and Quality Assurance
| Reagent/Solution | Function | Critical Specifications |
|---|---|---|
| Certified Reference Materials (CRMs) | Serve as the primary standard for calibrating instruments and assigning target values to PT samples. | Traceability to international standards (e.g., NIST), defined uncertainty, and high purity. |
| Quality Control (QC) Materials | Used for daily monitoring of analytical precision and accuracy. Assays are validated against CRMs. | Stable, commutable with patient samples, and available at multiple clinically relevant concentrations. |
| PT Survey Samples | The core test material distributed by PT providers. Used to assess a laboratory's performance against peers. | Homogeneity, stability, and a matrix similar to the routine patient samples. |
| Calibrators | Used to establish the relationship between the instrument's response and the analyte concentration. | Value-assigned by a higher-order reference method or CRM. |
| Liquid Handling Reagents | Includes buffers, diluents, and enzymes for sample preparation and analysis. | Lot-to-lot consistency, purity, and compatibility with the analytical methodology. |
The comparative analysis between traditional Proficiency Testing and other interlaboratory comparisons like blind Ring Trials reveals a critical distinction: PT is unparalleled in its direct assessment of a laboratory's routine operational competence. The ongoing standardization of PT programs, exemplified by updated regulations that introduce more challenges and stricter, percentage-based grading criteria, strengthens this assessment framework [14]. Furthermore, the integration of advanced technologies—including digital platforms for data management, AI for deep performance analytics, and automation for consistent sample handling—is poised to revolutionize PT management. These innovations collectively enhance the efficiency, traceability, and analytical power of PT schemes. For researchers and drug development professionals, the diligent application of these standardized and technology-enhanced PT practices is not merely a regulatory obligation but a fundamental component of a robust quality culture. It is this commitment to data integrity and continuous improvement that ultimately ensures the safety and efficacy of new therapeutics.
A Head-to-Head Comparison: Measuring Efficacy, Bias, and Impact
In pharmaceutical research and development, ensuring the accuracy and reliability of testing methods is paramount for both drug efficacy and patient safety. This guide provides an objective comparative analysis between two fundamental approaches: Traditional Proficiency Testing (PT) and Accuracy-Based (Blind) Testing. Traditional PT assesses laboratory performance by comparing results to a peer group consensus, whereas accuracy-based testing uses matrix-free human specimens with target values established by reference methods, providing a gold standard assessment of true accuracy [48]. Within the context of comparative analysis research, understanding the key performance indicators (KPIs) for each method is crucial for scientists and drug development professionals to select the appropriate methodology for their specific needs, from clinical trials to quality control.
The evolution of testing standards in 2025 further underscores the importance of this comparison. Regulatory updates, such as the CLIA Final Rule, have sharpened the focus on accuracy, introducing stricter performance criteria for specific analytes like hemoglobin A1c [49]. Simultaneously, the global laboratory proficiency testing market is projected to grow, reaching USD 2.13 billion by 2030, driven by strict regulatory requirements across healthcare and pharmaceutical industries [50]. This analysis synthesizes these developments, providing a data-driven comparison of these two critical methods.
Comparative Analysis of Key Performance Indicators
The selection of testing methodology directly impacts the interpretation of results and the subsequent decisions in the drug development pipeline. The table below summarizes the core KPIs and how they are assessed under each paradigm.
Table: Key Performance Indicator Comparison Between Traditional and Blind Testing Methods
| Key Performance Indicator (KPI) | Traditional Proficiency Testing | Accuracy-Based (Blind) Testing |
|---|---|---|
| Primary Benchmark | Peer group consensus [48] | Reference method target values (gold standard) [48] |
| Specimen Material | Often modified materials with potential matrix effects [48] | Genuine human specimens, matrix-free [48] |
| Core Performance Metric | Agreement with peer laboratories [48] | Accuracy against a true value [48] |
| Bias Detection Capability | Limited; cannot detect biases common to an entire peer group [48] | High; identifies method-specific biases even in FDA-cleared assays [48] |
| Regulatory & Standard Alignment | Checks procedural reliability [48] | Ensures compatibility with national/international guidelines [48] |
| Critical Use Cases | General procedural quality checks [48] | Hemoglobin A1c, cholesterol, creatinine, testosterone, 25-OH vitamin D [48] |
Analysis of KPI Differences
The divergence in KPIs reveals a fundamental difference in purpose. Traditional Proficiency Testing primarily serves as a reliability check, ensuring that a laboratory's procedures produce consistent results compared to other labs using similar methods [48]. Its strength lies in maintaining procedural consistency across the industry.
In contrast, Accuracy-Based Testing is an absolute validity check. By using unmasked human specimens and reference method targets, it directly measures trueness, which is critically important for analytes where national or international guidelines are used for clinical interpretation [48]. A key advantage is its ability to uncover clinically significant biases that traditional PT might miss, as entire peer groups can sometimes use methods with the same inherent inaccuracies [48].
Experimental Protocols and Methodologies
The experimental design for implementing these testing methods is distinct, each with specific workflows and material requirements.
Traditional Proficiency Testing Protocol
Traditional PT follows a cyclical process of sample distribution, analysis, and peer comparison. Participating laboratories analyze provided samples according to their standard operating procedures and submit their results to the PT provider. The provider then aggregates the data, establishes a peer group consensus value (often the mean or median of all submitted results), and generates a report showing the individual lab's performance against the peer group. Corrective actions are required if a lab's results fall outside acceptable peer-based limits [48] [49].
Accuracy-Based Testing Protocol
The protocol for accuracy-based programs, such as those run by the CDC's Division of Laboratory Sciences, involves a more rigorous multi-step process focused on comparison to a definitive standard.
Figure 1: Workflow Diagram for an Accuracy-Based Testing Program
The process begins with a "Request Form" for enrollment, where labs provide information such as shipping address and analytes of interest [51]. The provider then distributes samples that have been characterized using a reference method to establish a true target value [48]. Participating labs analyze the samples and submit a "Data Submission Form" with their measurement results and assay characteristics (e.g., instrument, calibrators) [51]. The provider compares the lab's results against the reference target and generates a statistical report. This report allows labs to evaluate their analytical accuracy and implement corrective measures, ultimately enhancing the reliability of their testing services [51].
The Scientist's Toolkit: Essential Research Reagent Solutions
The execution of both traditional and accuracy-based testing relies on a suite of essential reagents and materials. The following table details key components used in these quality assurance programs.
Table: Essential Reagents and Materials for Proficiency and Accuracy Testing
| Item | Function in Testing Protocols |
|---|---|
| Genuine Human Specimens | Authentic, matrix-free human samples used in accuracy-based programs to eliminate matrix effects and provide a realistic testing medium [48]. |
| Reference Materials | Calibrators and control materials with values assigned by reference methods; used to establish traceability and accuracy in blind testing programs [48] [51]. |
| Cell Culture Assays | Technology platform used extensively in microbiology PT for detecting infectious microorganisms; represents a large segment of the PT market [50]. |
| Polymerase Chain Reaction (PCR) Reagents | Kits and components for molecular diagnostics proficiency testing, crucial for areas like infectious disease testing (e.g., COVID-19 PCR test PT) [50]. |
| Chromatography Standards | Chemical standards used with chromatography technology to ensure accurate identification and quantification of analytes in complex mixtures during PT [50]. |
| Immunoassay Reagents | Antibodies, antigens, and buffers used in immunochemistry-based PT schemes to evaluate the performance of tests for hormones, tumor markers, and more [50]. |
This comparative analysis demonstrates that Traditional Proficiency Testing and Accuracy-Based Blind Testing are complementary yet distinct tools in the quality assurance arsenal. The choice between them should be driven by the specific analytical goals. Traditional PT is effective for monitoring routine performance and peer consistency, while accuracy-based testing is indispensable for validating method trueness, detecting bias, and ensuring compliance with clinical guidelines that demand the highest level of accuracy. For researchers and drug development professionals, integrating both methods—leveraging the consensus view of PT and the definitive benchmark of accuracy-based testing—provides the most robust framework for ensuring data integrity from the laboratory to the clinic.
In the pursuit of scientific truth, research methodologies must actively combat systematic errors that can distort results and lead to invalid conclusions. Performance bias and detection bias represent two critical threats to methodological integrity, occurring when knowledge of intervention assignments influences the behavior of participants/personnel or the assessment of outcomes, respectively [52]. Blinding (also called masking) serves as a fundamental methodological safeguard against these biases by concealing intervention allocations from various parties involved in a trial [53]. The strategic implementation of blind testing protocols represents a sophisticated approach to quality assurance that stands in stark contrast to traditional proficiency testing methods, particularly in their capacity to generate more reliable, unbiased evidence for decision-making in fields ranging from clinical medicine to forensic science.
The following diagram illustrates how knowledge of treatment allocation can introduce bias into different stages of a trial, and how blinding intervenes to prevent it:
Understanding Performance and Detection Bias
Defining the Bias Mechanisms
Performance bias occurs when participants or researchers modify their behavior based on knowledge of the intervention assignment, potentially introducing systematic differences in care or behavior between treatment groups beyond the intervention being studied [52]. For example, a clinician who knows a patient is receiving an experimental treatment might provide additional attention or care, artificially enhancing the apparent treatment effect [53]. Meanwhile, detection bias (also called ascertainment bias) arises when outcome assessors' knowledge of intervention assignments influences how they measure, interpret, or record outcomes, particularly for subjective endpoints [52] [54].
The distinction between these bias mechanisms is crucial, as they operate at different trial stages and require different blinding strategies. A landmark example of detection bias comes from a multiple sclerosis trial where blinded neurologists found no treatment benefit, while unblinded neurologists assessing the same patients reported apparent benefit for the intervention [52]. This dramatic discrepancy demonstrates how expectation and awareness can consciously or unconsciously influence outcome assessment.
Quantitative Impact of Unblinded Assessments
Empirical evidence consistently demonstrates that lack of blinding leads to exaggerated treatment effects across multiple medical disciplines. A comprehensive meta-analysis of empirical studies found that trials without blinding overestimated treatment effects by 14% on average (odds ratio 0.86, 95% confidence interval 0.74 to 0.99) compared to blinded trials [54]. The magnitude of bias varies significantly depending on how outcomes are measured:
Table 1: Impact of Unblinded Assessment on Trial Results by Outcome Type
| Outcome Type | Impact of Lack of Blinding | Evidence Source |
|---|---|---|
| Subjective Outcomes (e.g., pain, patient-reported outcomes) | 23% exaggeration of treatment effects | Systematic review of meta-analyses [52] |
| Objective Outcomes (e.g., mortality, laboratory measures) | Little evidence of significant bias | Same systematic review [52] |
| Mixed/Overall Outcomes | 8% exaggeration of treatment effects | Analysis of 250 RCTs [52] |
This pattern highlights why blinding is particularly crucial for trials relying on subjective assessments or patient-reported outcomes, where interpretation and expectation can substantially influence results [55].
Blind Testing vs. Traditional Proficiency Testing: Methodological Comparison
Fundamental Operational Differences
Traditional proficiency testing typically involves declared or open testing where participants know they are being evaluated, often through mail-distributed samples with explicit instructions that the materials are for assessment purposes [40]. In contrast, blind testing (or blind proficiency testing) incorporates quality control samples into routine workflow without revealing their special status, thereby capturing performance under normal operational conditions [3]. This fundamental distinction in approach leads to significant differences in ecological validity and bias potential.
A revealing comparative study from the Center for Disease Control demonstrated this distinction clearly when they sent identical simulated addict urine samples to collaborating laboratories through two different channels: one set was mailed as part of a regular proficiency testing program, while another set was forwarded through hospital administrators and methadone centers as though they were ordinary patient specimens [40]. The disparity in results was striking: while most laboratories performed acceptably with the mail-distributed samples, many performed poorly when the identical samples were submitted as routine patient specimens [40]. This demonstrates how awareness of evaluation can substantially alter performance and results.
Comparative Effectiveness in Bias Reduction
The forensic science literature provides compelling comparisons between these approaches. While most forensic laboratories rely entirely on declared proficiency tests, some federal facilities have adopted blind proficiency tests that offer distinct advantages [3]. Blind tests better simulate actual casework conditions, test the entire laboratory pipeline rather than just analyst capability, prevent behavioral changes that occur when examiners know they are being tested, and represent one of the only methods capable of detecting misconduct [3].
Table 2: Direct Comparison of Traditional vs. Blind Proficiency Testing
| Characteristic | Traditional Proficiency Testing | Blind Proficiency Testing |
|---|---|---|
| Sample Distribution | Declared, mail-distributed with explicit evaluation purpose [40] | Incorporated into routine workflow as ordinary specimens [40] [3] |
| Ecological Validity | Limited - participants may exercise special care [40] | High - captures performance under normal conditions [3] |
| Bias Reduction | Limited for performance and detection bias | Substantial reduction of both bias types [3] |
| Implementation Complexity | Relatively straightforward logistically | Presents logistical and cultural obstacles [3] |
| System Testing Scope | Primarily tests analyst capability | Tests entire laboratory pipeline [3] |
Experimental Evidence Quantifying Bias Reduction
Key Studies and Their Methodologies
The 1977 comparative study by the Center for Disease Control represents a foundational investigation into bias in testing programs [40]. Their experimental protocol involved creating simulated addict urine samples containing known drug concentrations, then distributing them through two parallel channels: one through the regular mail-based proficiency testing program, and another through collaborators who submitted them as routine patient specimens. This elegant design permitted direct comparison of performance on identical test materials under different awareness conditions, providing a clean measurement of bias magnitude [40].
In clinical trials, the quantification of blinding benefits often employs methodological comparisons across multiple studies. One common approach involves analyzing trials where blinded and unblinded assessors evaluated the same patients, as in the multiple sclerosis trial where blinded neurologists detected no treatment benefit while unblinded neurologists reported apparent improvements despite no actual treatment effect existing [52]. Similarly, a systematic survey of 250 randomized controlled trials found that studies without double-blinding showed odds ratios that were 17% higher on average than studies with proper blinding, indicating a systematic overestimation of treatment effects when blinding is absent [52].
Statistical Measurement Approaches
Statistical approaches to quantifying bias have grown increasingly sophisticated. Recent methodological work has focused on developing bias quantification metrics such as the Area Under the Curve (AUC) of an optimal binary classifier between distributions, which ranges from 0.5 (no bias) to 1 (maximum bias) [56]. In machine learning applications, researchers have developed expectation-maximization algorithms that model class-conditional distributions in both labeled and unlabeled data to detect and quantify bias, with AUC values between 0.5-0.6 typically indicating practically indistinguishable distributions [56].
For systematic reviews and meta-analyses, the CochCollaboration's risk of bias tool provides a structured framework for assessing blinding across multiple domains, allowing quantitative synthesis of how blinding status influences effect estimates [54]. These tools enable researchers to conduct sensitivity analyses excluding studies with high risk of bias, or to statistically model the potential impact of bias on overall results.
Implementation Protocols for Blind Testing
Experimental Workflow for Blind Proficiency Testing
Implementing effective blind testing requires meticulous planning and execution. The following diagram outlines a generalized workflow for blind proficiency testing programs, synthesizing elements from successful implementations across fields:
Practical Implementation Challenges and Solutions
Despite its benefits, blind testing faces significant implementation barriers across fields. In forensic laboratories, directors and quality assurance managers have identified logistical and cultural obstacles to adopting blind proficiency tests, including resource constraints, workflow disruptions, and resistance to what some perceive as "entrapment" [3]. Similarly, in clinical trials, researchers report that practical constraints and additional costs represent primary obstacles to implementing outcome assessment blinding, with 52% citing limited resources as a major barrier [55].
Successful implementation strategies often involve stakeholder engagement and creative problem-solving. For complex intervention trials, practical blinding methods can include using sham procedures, placebo acupuncture, mock physiotherapy sessions, or independent blinded endpoint adjudication committees for objective events [55]. In surgical trials where blinding surgeons is impossible, outcome assessors and data analysts can still be blinded through centralized assessment of images or performance tests by evaluators uninvolved in intervention delivery [55] [54].
Implementing effective blind testing requires both methodological rigor and practical tools. The following table details key resources and their applications in bias reduction:
Table 3: Research Reagent Solutions for Blind Testing Implementation
| Tool/Resource | Primary Function | Application Examples |
|---|---|---|
| Blinded Samples | Quality control materials with known properties distributed as routine specimens | Simulated addict urine in drug testing [40]; milk samples with known contaminant levels in dairy testing [9] |
| Sham Procedures | Placebo interventions matching the appearance and routine of active interventions | Placebo acupuncture; mock physiotherapy sessions [55] |
| Independent Adjudication Committees | Expert panels blinded to treatment allocation who evaluate endpoints | Committees reviewing medical images, clinical events, or performance tests [55] |
| Centralized Assessment | Specialized centers conducting blinded evaluation of standardized materials | Central labs analyzing imaging, electrocardiograms, or rating scales [55] |
| Allocation Concealment Systems | Mechanisms to prevent deduction of treatment assignment sequence | Sequentially numbered, opaque, sealed envelopes; pharmacy-controlled randomization [52] |
| Blinded Data Analysis | Statistical analysis conducted without knowledge of group assignments | Separate data analysis teams working with coded group designations [52] |
The quantitative evidence is unequivocal: blind testing methodologies substantially reduce both performance and detection bias across diverse fields from clinical medicine to laboratory science. The magnitude of this effect is particularly significant for subjective outcomes, where lack of blinding can exaggerate treatment effects by 23% or more [52]. While traditional proficiency testing retains value for basic competency assessment, it cannot capture the ecological validity of blind testing approaches that evaluate performance under normal operational conditions [40] [3].
Future methodological development should address the practical implementation barriers that currently limit blind testing adoption, particularly in resource-constrained settings. The development of more efficient blinding procedures, standardized reporting guidelines for blinding protocols, and cost-effective approaches to blind sample development would help expand implementation. Furthermore, as evidence-based practice continues to evolve, regulatory and funding policies should prioritize and potentially mandate blind testing approaches where feasible and ethical, particularly for interventions that will influence clinical practice or public policy. Only through such rigorous, bias-aware methodology can research truly fulfill its promise of generating reliable evidence to guide decision-making.
In the rigorous world of scientific research and diagnostic testing, ecological validity measures the degree to which test conditions and outcomes reflect real-world operational environments and patient-relevant functional capacities [57]. For researchers, scientists, and drug development professionals, this concept is paramount for bridging the translational gap between controlled laboratory studies and actual clinical efficacy. A biomarker with high ecological validity, for instance, does not merely demonstrate a pharmacological effect but accurately predicts a meaningful clinical outcome for a patient in their daily life [57]. The assessment of ecological validity is undergoing a significant transformation, driven by a paradigm shift in how testing is conceived and conducted. This guide provides a comparative analysis of two fundamental approaches for establishing this validity: the established method of traditional proficiency testing (PT) and the more rigorous approach of comparative analysis blind testing.
The recent FDA announcement to phase out mandatory animal testing for many drug types underscores a broader movement toward testing methodologies with greater human relevance and predictive power [58]. This evolution highlights the growing imperative for testing strategies that are not only technically precise but also ecologically valid. The core challenge lies in selecting a testing framework that can effectively minimize bias, detect systemic errors, and ensure that results are generalizable to real-world scenarios. This article objectively compares traditional proficiency testing with blind testing protocols, providing the experimental data and methodological details needed to inform laboratory strategy and research design.
Methodology: Frameworks for Assessing Test Validity
Defining the Testing Approaches
- Traditional (Declared) Proficiency Testing (PT): In this conventional model, laboratories receive samples specifically identified as part of a proficiency testing scheme. The laboratory personnel are aware that the samples are for testing their competency. Participation is often a mandatory requirement for maintaining laboratory accreditation to standards such as ISO/IEC 17025 and ISO 15189 [59]. The primary goal is to obtain an external and independent assessment of the laboratory's performance in conducting specific tests or measurements.
- Comparative Analysis Blind Testing: This approach involves submitting test samples to a laboratory without disclosing that they are part of an assessment. The samples are designed to mimic real operational cases as closely as possible, thereby testing the entire laboratory pipeline under normal working conditions [3]. This method is designed to avoid changes in behavior that occur when an examiner knows they are being tested and is one of the only methods that can detect systematic misconduct [3].
Experimental Protocols for Testing Regimes
Protocol for Traditional Proficiency Testing
- Sample Distribution: PT providers send out predefined samples to participating laboratories on a scheduled basis, typically involving three challenges per year, with five samples in each challenge [14].
- Sample Analysis: Participating laboratories analyze the samples using their standard operational procedures. The laboratories know the samples are PT specimens and the analysis occurs within a predefined deadline.
- Data Submission and Reporting: Laboratories submit their results to the PT organizer. The organizer then analyzes the data, compares the laboratory's results to the assigned values or peer group performance, and issues a report and a certificate of participation or performance [60].
- Performance Grading: Grading is often based on predefined acceptable performance limits, which may be set as percentage-based limits or fixed concentration units (e.g., ±20% or ±0.4 mg/dL for bilirubin) [14].
Protocol for Implementing Blind Proficiency Testing
- Test Design: The first step involves designing a test that closely resembles an actual case received by the laboratory. This requires careful planning to ensure the sample matrix, analyte concentrations, and accompanying documentation appear authentic [3].
- Covert Introduction: The blind sample is introduced into the laboratory's normal workflow through a covert channel, indistinguishable from routine operational samples.
- Normal Workflow Processing: The sample is processed by the laboratory's standard pipeline, from receipt and sample handling to analysis, data interpretation, and reporting. The key is that no one in the laboratory is aware of the test.
- Result Evaluation and Analysis: The results generated by the laboratory are compared against the expected or reference results. The evaluation assesses not just analytical accuracy, but also the entire process, including turnaround time and adherence to standard operating procedures [3].
Comparative Analysis: Blind Testing vs. Traditional Proficiency Testing
The following table summarizes the core differences in the design and implementation of these two testing approaches, which directly influence their ecological validity.
Table 1: Core Methodological Comparison of Testing Approaches
| Feature | Traditional Proficiency Testing | Blind Proficiency Testing |
|---|---|---|
| Sample Awareness | Declared; laboratory knows it is a test [59] | Blind; laboratory believes it is a real operational sample [3] |
| Testing Conditions | Often idealized and scheduled | Mimics real-world, high-pressure operational workflow [3] |
| Primary Objective | Assess technical competency for a specific test or measurement [59] | Assess the entire laboratory system under authentic conditions [3] |
| Bias Risk | Higher risk of "special effort" bias when staff know they are being tested [3] | Lower risk; captures normal laboratory performance and potential complacency |
| Error Detection | Identifies analytical or technical errors | Can detect analytical, clerical, interpretive, and systemic procedural errors [3] |
The quantitative outcomes and practical implications for laboratories are distinct, as shown in the following comparison of results and feasibility.
Table 2: Outcomes and Feasibility Comparison
| Aspect | Traditional Proficiency Testing | Blind Proficiency Testing |
|---|---|---|
| Ecological Validity | Lower; measures capability in a controlled, "best behavior" scenario | Higher; measures performance under genuine, real-world conditions [3] |
| Implementation Logistics | Straightforward; offered by professional PT providers globally [60] | Logistically challenging and culturally difficult to implement in many settings [3] |
| Regulatory & Accreditation Role | Mandatory for accreditation (e.g., ISO/IEC 17025) [59] | Not yet widely mandated, but recognized as a gold standard for quality assurance [3] |
| Cost & Resource Requirement | Moderate and predictable (subscription fees) | Can be high due to design, deployment, and analysis complexity [3] |
Experimental Data and Evidence
Empirical evidence underscores the necessity of robust testing designs. Studies on clinical trials have demonstrated that a lack of blinding can quantitatively affect study outcomes. For instance, a systematic review found that non-blinded versus blinded outcome assessors generated exaggerated hazard ratios by an average of 27% in studies with time-to-event outcomes and exaggerated odds ratios by an average of 36% in studies with binary outcomes [23]. This demonstrates that knowledge of the treatment group can lead to significant bias in outcome assessment.
In the context of forensic science, where blind testing has been piloted, it has been shown to test the "entire laboratory pipeline" in a way declared testing cannot [3]. While specific quantitative data on performance differences in laboratory settings is less common, the theoretical and empirical basis from clinical research strongly suggests that blind testing provides a more accurate and less biased assessment of a laboratory's true operational performance.
Visualizing Testing Workflows
The following diagram illustrates the key procedural differences in the workflows of traditional declared testing versus blind testing, highlighting where potential biases can be introduced.
Diagram 1: A comparison of declared versus blind PT workflows, showing the critical point where bias is introduced in the traditional model.
The Scientist's Toolkit: Essential Research Reagent Solutions
The following table details key reagents, tools, and methodologies that are central to conducting ecologically valid testing in modern research and development.
Table 3: Key Research Reagent Solutions for Modern Testing
| Tool/Solution | Primary Function | Relevance to Ecological Validity |
|---|---|---|
| Proficiency Testing (PT) Schemes [59] | Provides external, standardized samples for inter-laboratory comparison. | Benchmarks analytical performance but has limited ecological validity due to its declared nature. |
| Digital Twins [58] | A virtual model of a patient, process, or system that integrates multi-omics and real-world data. | Enables high-ecological validity simulation of disease progression and drug response before real-world human trials. |
| Organ-on-a-Chip Systems [61] | Microfluidic devices lined with living human cells that emulate organ-level physiology. | Provides a human-relevant, in vitro system that can predict tissue-specific responses better than animal models. |
| In Silico Toxicity Prediction Platforms (e.g., ProTox-3.0, ADMETlab) [58] | Computational models using AI to predict drug toxicity, absorption, and metabolism. | Offers a scalable, human-specific alternative to animal-based toxicology, though validation is ongoing. |
| Prescription Digital Therapeutics (PDTs) [58] | Evidence-based software and digital interventions to prevent, manage, or treat medical conditions. | Their development is increasingly aided by in silico models to simulate therapeutic effects across diverse clinical scenarios, enhancing real-world relevance. |
The comparative analysis between traditional proficiency testing and blind testing reveals a critical trade-off. Traditional PT is an accessible, standardized, and essential tool for maintaining baseline analytical competency and meeting accreditation requirements [59]. However, its declared nature limits its ecological validity and its ability to assess the laboratory's true operational performance.
In contrast, blind testing offers a superior level of ecological validity by testing the entire laboratory system under authentic conditions, making it a powerful tool for identifying latent errors and systemic issues that declared testing cannot detect [3]. Despite its significant logistical and cultural implementation challenges, it represents a future direction for high-reliability testing regimes.
For researchers and drug development professionals, the choice is not necessarily binary. A robust quality assurance program should integrate traditional PT to ensure foundational analytical accuracy while strategically incorporating blind testing, where feasible, to validate and improve the ecological validity of the entire testing pipeline. As the scientific landscape evolves with increased reliance on in silico models and human-relevant New Approach Methodologies (NAMs) [61], the principles of blinding and ecological validity will become even more critical in generating trustworthy, translatable data.
In scientific research and drug development, the selection of an appropriate testing methodology is a critical determinant of experimental validity and reliability. This guide provides a comparative analysis of two fundamental testing approaches: traditional proficiency testing (PT) and blind testing. Traditional proficiency testing serves as a well-established quality assurance tool, where laboratories analyze standardized samples to evaluate their performance against known standards or peer consensus [44]. The core objective of PT is to ensure the accuracy and reliability of laboratory test results, which is particularly crucial in medical and clinical settings where errors can have significant implications for patient diagnosis and treatment [44].
Within the framework of comparative analysis research, understanding the distinctions, applications, and limitations of these testing methodologies is paramount for researchers, scientists, and drug development professionals. This guide synthesizes current evidence to establish a decision framework for selecting the optimal testing approach based on specific research objectives, regulatory requirements, and practical constraints. The comparative analysis extends beyond theoretical differences to encompass practical implementation considerations, data quality outcomes, and the evolving landscape of testing methodologies enhanced by artificial intelligence and digital ecosystems.
Conceptual Foundations: Traditional Proficiency Testing vs. Blind Testing
Traditional Proficiency Testing: Principles and Implementation
Traditional proficiency testing (PT) operates on a fundamental principle: the systematic evaluation of laboratory performance through the analysis of distributed samples with predetermined or consensus-established values [44]. In clinical and medical laboratories, PT programs simulate patient samples, which can be administered either internally (on-site) or externally (through samples sent to another laboratory) [44]. This approach provides a critical mechanism for verifying that laboratory testing processes yield accurate, reliable, and consistent results over time.
The operational structure of traditional PT follows a well-defined sequence:
- Sample Distribution: Accrediting organizations or regulatory bodies prepare and distribute standardized test samples to participating laboratories.
- Analysis Phase: Participating laboratories analyze the samples using their routine methods, personnel, and equipment.
- Result Submission: Laboratories submit their findings to the organizing body for evaluation.
- Performance Assessment: The organizing body compares submitted results against target values using statistical methods such as z-scores, where scores between -2 and +2 generally indicate acceptable performance [44].
- Feedback Loop: Laboratories receive detailed reports highlighting their performance relative to peers and identifying areas requiring improvement.
This structured approach makes traditional PT particularly valuable for regulatory compliance, method validation, and ongoing quality assurance in regulated environments such as clinical diagnostics, pharmaceutical manufacturing, and food safety testing [44] [9].
Blind Testing: Principles and Methodological Considerations
Blind testing introduces a different methodological approach where the testing entity analyzes samples without prior knowledge of their composition, concentration, or expected results. This methodology aims to eliminate conscious or unconscious bias that might influence analytical procedures, result interpretation, or reporting. While the search results do not contain specific details about blind testing protocols, this approach is methodologically distinct from traditional PT in its fundamental implementation.
In research contexts, blind testing often takes two primary forms:
- Single-Blind Testing: The analyst is unaware of sample identities or expected outcomes during testing.
- Double-Blind Testing: Neither the analyst nor the study coordinator knows the sample specifications until after all analyses are complete.
This approach is particularly valuable for validating novel methodologies, assessing true laboratory competency without reference standards, and investigating potential systematic biases in established testing protocols.
Comparative Analysis: Performance Metrics and Experimental Data
The selection between traditional proficiency testing and blind testing requires a thorough understanding of their comparative performance across multiple dimensions. The table below synthesizes key characteristics based on current evidence and implementation practices:
Table 1: Comparative Performance Metrics of Traditional Proficiency Testing vs. Blind Testing
| Characteristic | Traditional Proficiency Testing | Blind Testing |
|---|---|---|
| Primary Objective | Monitor ongoing analytical competence, identify systematic errors [44] | Assess unbiased performance, validate method robustness |
| Sample Awareness | Known as PT samples, though values are blinded [44] | Completely unknown samples and expected values |
| Regulatory Acceptance | Widely recognized for laboratory certification [44] [9] | Limited regulatory framework, primarily research applications |
| Error Identification | Excellent for detecting analytical errors (68% of PT failures) [44] | Comprehensive error detection across pre-analytical, analytical, and post-analytical phases |
| Implementation Frequency | Typically quarterly or annual cycles [9] | Variable, often study-specific |
| Corrective Action Guidance | Structured feedback mechanisms with defined corrective actions [44] | Self-directed investigation and problem-solving |
| Resource Requirements | Moderate (participation fees, dedicated analysis time) | High (custom sample preparation, complex study design) |
Quantitative Performance Assessment
The effectiveness of traditional proficiency testing is demonstrated through performance data across various implementation domains. In medical laboratory settings, studies have shown a steady increase in the proportion of correct results reported by laboratories participating in iterative PT programs from 2012 to 2018, indicating that regular participation and feedback improve laboratory competency over time [9].
Performance assessment in traditional PT typically employs statistical measures such as:
- Z-scores: Standardized measure of deviation from the assigned value, with |z| ≤ 2.0 generally indicating acceptable performance [44]
- Proficiency Standards: Successful performance often requires ≥80% of results falling within acceptable limits [44]
- Trend Analysis: Longitudinal tracking of laboratory performance across multiple testing cycles
Research indicates that analytical errors constitute the most frequent cause of unacceptable PT results (approximately 68% of cases), with pre-analytical and post-analytical errors accounting for the remainder [44]. This distribution highlights the specific competency assessment strengths of traditional PT in evaluating analytical phase performance.
Experimental Protocols and Methodological Implementation
Traditional Proficiency Testing Protocol
The implementation of traditional proficiency testing follows a standardized protocol designed to ensure consistent evaluation across participating laboratories:
Table 2: Experimental Protocol for Traditional Proficiency Testing
| Phase | Key Activities | Quality Control Measures |
|---|---|---|
| Program Design | • Define test analytes and concentrations• Establish acceptance criteria• Select statistical assessment method | • Align with regulatory requirements• Validate sample stability• Establish homogeneity testing |
| Sample Preparation | • Manufacture certified reference materials• Portion identical samples to all participants• Ensure sample stability during shipping | • Verify sample homogeneity• Confirm reference values• Document stability testing |
| Analysis & Reporting | • Analyze samples using routine methods• Document all procedures• Submit results within deadline | • Treat PT samples like patient samples [44]• Follow standard operating procedures• Implement internal quality control |
| Data Analysis | • Calculate consensus values• Determine z-scores for each participant• Identify outliers and trends | • Use robust statistical methods• Apply predefined evaluation algorithms• Account for method differences |
| Feedback & Improvement | • Distribute performance reports• Identify areas for improvement• Implement corrective actions | • Provide educational resources [44]• Document corrective actions• Monitor effectiveness of improvements |
A significant challenge in traditional PT implementation is the tendency for laboratories to treat PT samples differently than routine patient samples, which can compromise the validity of performance assessment [44]. Protocols must emphasize that PT samples should be incorporated into the routine workflow without special handling or additional repetitions to accurately reflect typical laboratory performance.
Methodological Framework for Blind Testing
While specific protocols for blind testing vary based on application domain, the general methodological framework includes:
Study Design Phase:
- Define study objectives and performance criteria
- Develop sample preparation protocol with independent third party
- Establish blinding procedures to prevent unintended disclosure
Sample Preparation and Distribution:
- Create samples representing realistic scenarios and challenges
- Implement coding system to maintain blinding
- Document sample characteristics for subsequent evaluation
Testing and Analysis Phase:
- Conduct analyses using standard operating procedures
- Document all methodological details and observations
- Submit results for decoding and evaluation
Evaluation and Assessment:
- Compare results against established reference values
- Identify discrepancies and potential causes
- Generate performance metrics specific to study objectives
The fundamental distinction in blind testing is the complete separation between sample preparation and analysis, with rigorous controls to prevent inadvertent unblinding throughout the testing process.
Visualization of Testing Methodologies and Workflows
Traditional Proficiency Testing Workflow
Traditional Proficiency Testing Workflow
Error Distribution in Unacceptable Proficiency Testing Results
Proficiency Testing Error Distribution
The Scientist's Toolkit: Essential Research Reagent Solutions
The implementation of robust testing methodologies requires specific materials and reagents designed to ensure accurate, reproducible results. The following table details essential components for establishing effective testing programs:
Table 3: Essential Research Reagent Solutions for Testing Programs
| Reagent/Material | Function | Application Context |
|---|---|---|
| Certified Reference Materials | Provide matrix-matched samples with known analyte concentrations for method validation [9] | Both PT and blind testing programs |
| Stable Isotope-Labeled Analytes | Serve as internal standards for mass spectrometry-based methods, correcting for matrix effects | Analytical method development and validation |
| Quality Control Materials | Monitor assay performance over time, detect drift and imprecision [44] | Routine quality assurance in both approaches |
| Matrix-Matched Samples | Account for sample matrix effects on analytical measurements | Blind testing scenario development |
| Stability Testing Reagents | Evaluate sample integrity under various storage conditions | PT program sample validation [9] |
| Calibration Standards | Establish quantitative relationship between instrument response and analyte concentration | Traditional PT method alignment |
| Proficiency Test Panels | Multi-analyte samples for comprehensive performance assessment | Regulatory compliance testing [44] |
These reagent solutions form the foundation of reliable testing programs, enabling laboratories to validate methods, monitor performance, and ensure result comparability across different testing methodologies and platforms.
Decision Framework: Selecting the Appropriate Testing Approach
The choice between traditional proficiency testing and blind testing should be guided by specific research objectives, regulatory requirements, and resource constraints. The following decision framework provides structured guidance for selecting the optimal approach:
Application-Specific Recommendations
Regulatory Compliance and Certification: Traditional proficiency testing is the established method for meeting regulatory requirements in clinical laboratories, pharmaceutical quality control, and food safety testing [44] [9]. The structured feedback and defined performance metrics align with accreditation standards.
Method Development and Validation: Blind testing offers superior capabilities for validating novel analytical methods, as it eliminates method-specific optimization that might occur with known PT samples.
Comprehensive Error Identification: While traditional PT effectively identifies analytical errors, blind testing may provide more comprehensive assessment of total testing process including pre-analytical and post-analytical phases.
Resource-Limited Settings: Traditional PT programs provide cost-effective quality assessment through standardized materials and centralized data analysis, making them suitable for environments with limited quality assurance resources.
Emerging Trends and Future Directions
The field of testing methodology is evolving with several significant trends:
- Digital Proficiency Testing: Emerging frameworks propose conducting PT within digital ecosystems and data spaces, creating digital twins of physical testing processes to optimize performance before implementation [62].
- AI-Enhanced Test Design: Artificial intelligence systems are being applied to optimize proficiency test design, statistical analysis, and result interpretation [63].
- Hybrid Approaches: Some programs are integrating elements of both traditional PT and blind testing to leverage the strengths of each methodology.
The selection between traditional proficiency testing and blind testing represents a strategic decision with significant implications for research validity, regulatory compliance, and quality improvement. Traditional proficiency testing offers a well-established framework for comparative performance assessment with structured feedback mechanisms, while blind testing provides unbiased evaluation of true methodological performance.
This comparative analysis demonstrates that these approaches are not mutually exclusive but rather complementary tools in the quality assurance arsenal. The optimal selection depends on specific research objectives, with traditional PT excelling in regulatory contexts and ongoing performance monitoring, while blind testing offers advantages for method validation and comprehensive error detection.
As testing methodologies continue to evolve with technological advancements, researchers should maintain flexibility in approach selection while adhering to the fundamental principles of analytical quality assurance that underpin both traditional proficiency testing and blind testing methodologies.
Conclusion
The comparative analysis unequivocally demonstrates that blind and traditional proficiency testing are complementary yet distinct tools. Traditional declared testing remains a cornerstone for routine competency assessment and regulatory compliance, as evidenced by its central role in updated CLIA frameworks. However, blind testing emerges as a superior methodology for validating the entire laboratory pipeline, detecting subtle biases, and ensuring ecological validity by simulating real-case scenarios. The suspension of the FDA's Milk PT program serves as a critical reminder of the fragility of these quality systems and the need for robust, resilient designs. Future directions must involve greater adoption of blind testing where feasible, increased stakeholder education on its benefits, and the development of more sophisticated, cost-effective blinding strategies to further strengthen the foundation of evidence-based biomedical research and diagnostic accuracy.
References
- 1. CMS Proficiency Testing | CLIA Compliance | ACP [https://www.acponline.org/practice-career/business-resources/laboratory-proficiency-testing-program/what-is-proficiency-testing]
- 2. What Does Your Proficiency Testing (PT) Prove? A Look at ... [https://www.spectroscopyonline.com/view/what-does-your-proficiency-testing-pt-prove-a-look-at-inorganic-analyses-proficiency-tests-and-contamination-and-error-part-i]
- 3. Implementing blind proficiency testing in forensic laboratories [https://www.sciencedirect.com/science/article/pii/S2589871X20300577]
- 4. Insights: Implementing Blind Proficiency Testing in ... [https://forensicstats.org/blog/2020/10/01/insights-implementing-blind-proficiency-testing-in-forensic-laboratories/]
- 5. Laboratory Proficiency Testing Market Size & Share Analysis [https://www.mordorintelligence.com/industry-reports/laboratory-proficiency-testing-market]
- 6. The design and implementation of a proficiency test for ... [https://www.sciencedirect.com/science/article/abs/pii/S1355030616300016]
- 7. A novel proficiency test to assess the animal diagnostic ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11847136/]
- 8. Solving Daubert's Dilemma for the Forensic Sciences ... [https://houstonlawreview.org/article/12199-solving-_daubert_-s-dilemma-for-the-forensic-sciences-through-blind-testing]
- 9. Suspension of FDA's Grade “A” Milk Proficiency Testing Program [https://farms.extension.wisc.edu/articles/suspension-of-fdas-grade-a-milk-proficiency-testing-program-a-comprehensive-analysis/]
- 10. 腾讯:混元图像 3.0 全球“盲测”登顶第一_新浪财经_新浪网 [https://finance.sina.com.cn/tech/internet/2025-10-05/doc-infsvmwp5212421.shtml]
- 11. Comparison of laboratory performance with blind and mail- ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC1432053/]
- 12. Top Global Proficiency Testing Companies Setting New ... [https://biopharmaapac.com/news/120/7149/top-global-proficiency-testing-companies-setting-new-standards-in-laboratory-accuracy.html]
- 13. 可信实验白皮书系列01:从0到1的方法论与实践指南 [https://tech.meituan.com/2025/05/22/meituan-ab-online-controlled-experiment-01.html]
- 14. Get ready for proficiency testing changes [https://myadlm.org/cln/articles/2024/mayjune/get-ready-for-proficiency-testing-changes]
- 15. Proficiency testing and cross-laboratory method comparison to ... [https://mbmg.pensoft.net/article/133264/]
- 16. Implementing blind proficiency testing in forensic laboratories [https://scholarship.law.upenn.edu/qc_articles/23/]
- 17. Blind Proficiency Testing Workshop Leads to Valuable ... [https://forensicstats.org/news-posts/recent-blind-proficiency-testing-workshop-leads-to-valuable-discussion-between-forensic-laboratories-and-csafe-researchers/]
- 18. Proficiency Testing and Interlaboratory Comparisons - Foclar [https://foclar.com/news/proficiency-testing-and-interlaboratory-comparisons]
- 19. Planning, design and logistics of a decision analysis study [https://www.sciencedirect.com/science/article/pii/S2589871X22000067]
- 20. Quantitative Research Designs, Hierarchy of Evidence and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12056466/]
- 21. A use-wear blind test on knapped stone microdebitage [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0243101]
- 22. Detection bias and the role of negative control outcomes [https://pmc.ncbi.nlm.nih.gov/articles/PMC12172073/]
- 23. Blinding in Clinical Trials: Seeing the Big Picture - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC8308085/]
- 24. Blinding: Who, what, when, why, how? - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC2947122/]
- 25. Blinding of outcome assessors and its association with ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10196921/]
- 26. Practices and Perceived Value of Proficiency Testing in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6941662/]
- 27. Implementing blind proficiency testing in forensic laboratories: Motivation, obstacles, and recommendations - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC7552087/]
- 28. Evaluation of blood lead proficiency testing: comparison of open and blind paradigms - PubMed [https://pubmed.ncbi.nlm.nih.gov/11159782/]
- 29. Double-Blind Study - Clinical Research Explained [https://viares.com/blog/clinical-research-explained/double-blind-study/]
- 30. Point-of-Care Testing - StatPearls - NCBI Bookshelf [https://www.ncbi.nlm.nih.gov/books/NBK592387/]
- 31. Machine learning in point-of-care testing: innovations, ... [https://www.nature.com/articles/s41467-025-58527-6]
- 32. Point-of-care testing: a critical analysis of the market and ... [https://www.frontiersin.org/journals/lab-on-a-chip-technologies/articles/10.3389/frlct.2024.1394752/full]
- 33. Does blind hiring still make sense in 2025? [https://www.hiretruffle.com/blog/blind-hiring]
- 34. 2025 Digital Trends in Operations survey [https://www.pwc.com/us/en/services/consulting/business-transformation/digital-supply-chain-survey.html]
- 35. U.S. FDA Suspends Milk Quality Tests Amid Workforce Cuts [https://www.dairyherd.com/news/education/u-s-fda-suspends-milk-quality-tests-amid-workforce-cuts]
- 36. US FDA suspends milk quality tests amid workforce cuts [https://www.unmc.edu/healthsecurity/transmission/2025/04/23/us-fda-suspends-milk-quality-tests-amid-workforce-cuts/]
- 37. Rigorous Milk and Dairy Safety Testing Continues - IDFA [https://www.idfa.org/news/rigorous-milk-and-dairy-safety-testing-continues]
- 38. NMPF Reaffirms Milk Safety After FDA Program Suspension [https://www.nmpf.org/nmpf-reaffirms-milk-safety-after-of-fda-program-suspension/]
- 39. FDA Reaffirms Milk Safety, Supported by NMPF [https://www.nmpf.org/fda-reaffirms-milk-safety-supported-by-nmpf/]
- 40. Comparison of Laboratory Performance With Blind and ... [https://pubmed.ncbi.nlm.nih.gov/200968/]
- 41. A comparative chemogenic analysis for predicting Drug ... [https://www.nature.com/articles/s41598-020-63842-7]
- 42. Overview of methods for comparing the efficacies of drugs ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3895352/]
- 43. Comparative Research to Shape Clinical Trials [https://www.appliedclinicaltrialsonline.com/view/comparative-research-shape-clinical-trials-0]
- 44. Investigating the Performance of Unacceptable Results in ... [https://www.bioresscientia.com/article/investigating-the-performance-of-unacceptable-results-in-proficiency-testing-among-medical-laboratories]
- 45. Comparison Between Ring Trials and Proficiency Testing [https://shapypro.com/comparison-between-ring-trials-and-proficiency-testing/]
- 46. 国产汽车芯片认证审查技术体系实现突破,破解“不敢用 [https://www.eet-china.com/mp/a453509.html]
- 47. 2025年晶泰控股研究报告:AI+人工智能自主实验平台驱动药物及 ... [https://finance.sina.com.cn/stock/relnews/hk/2025-09-15/doc-infqpsyu1762661.shtml]
- 48. Accuracy-Based Programs [https://www.cap.org/laboratory-improvement/proficiency-testing/accuracy-based-programs]
- 49. 2025 Changes to Point-of-Care Testing Regulatory ... [https://myadlm.org/education/point-of-care-testing-professional-certification/the-point/articles/2025/may]
- 50. Laboratory Proficiency Testing Market To Reach $2.13Bn ... [https://www.grandviewresearch.com/press-release/global-laboratory-proficiency-testing-market]
- 51. Proposed Data Collection Submitted for Public Comment ... [https://www.federalregister.gov/documents/2025/10/02/2025-19252/proposed-data-collection-submitted-for-public-comment-and-recommendations]
- 52. Lack of blinding [https://catalogofbias.org/biases/lack-of-blinding/]
- 53. Blinding - Clinical Research Explained [https://viares.com/blog/clinical-research-explained/blinding/]
- 54. Blinding in randomized controlled trials in general and ... [https://systematicreviewsjournal.biomedcentral.com/articles/10.1186/s13643-016-0226-4]
- 55. Navigating blinding challenges in complex intervention trials [https://pmc.ncbi.nlm.nih.gov/articles/PMC12613531/]
- 56. An Approach to Identifying and Quantifying Bias in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9782737/]
- 57. Ecological validity of biomarkers in drug research [https://scholarlypublications.universiteitleiden.nl/handle/1887/4282537]
- 58. In Silico Research Is Rewriting the Rules of Drug Development [https://pmc.ncbi.nlm.nih.gov/articles/PMC12070237/]
- 59. 6 reasons why Proficiency Testing is important [https://www.lgcstandards.com/US/en/Resources/Articles/AXIO_PT_explained]
- 60. External proficiency testing exercises: challenges and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10884168/]
- 61. How new approach methodologies are reshaping drug ... [https://www.mckinsey.com/industries/life-sciences/our-insights/the-synthesis/how-new-approach-methodologies-are-reshaping-drug-discovery]
- 62. Trustworthy, self-fulfilling, non-redundant proficiency tests ... [https://www.sciencedirect.com/science/article/pii/S2665917424006226]
- 63. 跨学科创新远超人类?AI科学家提假设/做实验/发顶会开启 ... [https://hub.baai.ac.cn/view/50417]